By the end of this presentation, you will:
- Understand how your browser interacts with the internet
- Be able to gather data from the internet using 3 methods:
- HTTP requests + HTML parsing
- Selenium + HTML parsing
- API requests
- Understand the advantages and shortfalls of each method
How does a website work?¶
A lot goes on behind the scenes when you view a website like https://www.brookings.edu/.
Understanding how your computer interacts with remote resources will help you become a more capable data collector.
Key terminology¶
Client¶
"Clients are the typical web user's internet-connected devices (for example, your computer connected to your Wi-Fi, or your phone connected to your mobile network) and web-accessing software available on those devices (usually a web browser like Firefox or Chrome)."[1]
Server¶
"Servers are computers that store webpages, sites, or apps. When a client device wants to access a webpage, a copy of the webpage is downloaded from the server onto the client machine to be displayed in the user's web browser."[2]
[1] Mozilla (2023). How the web works. Retrieved from https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web/How_the_Web_works
[2] Ibid.
Clients send requests for information from servers. The servers send back responses.
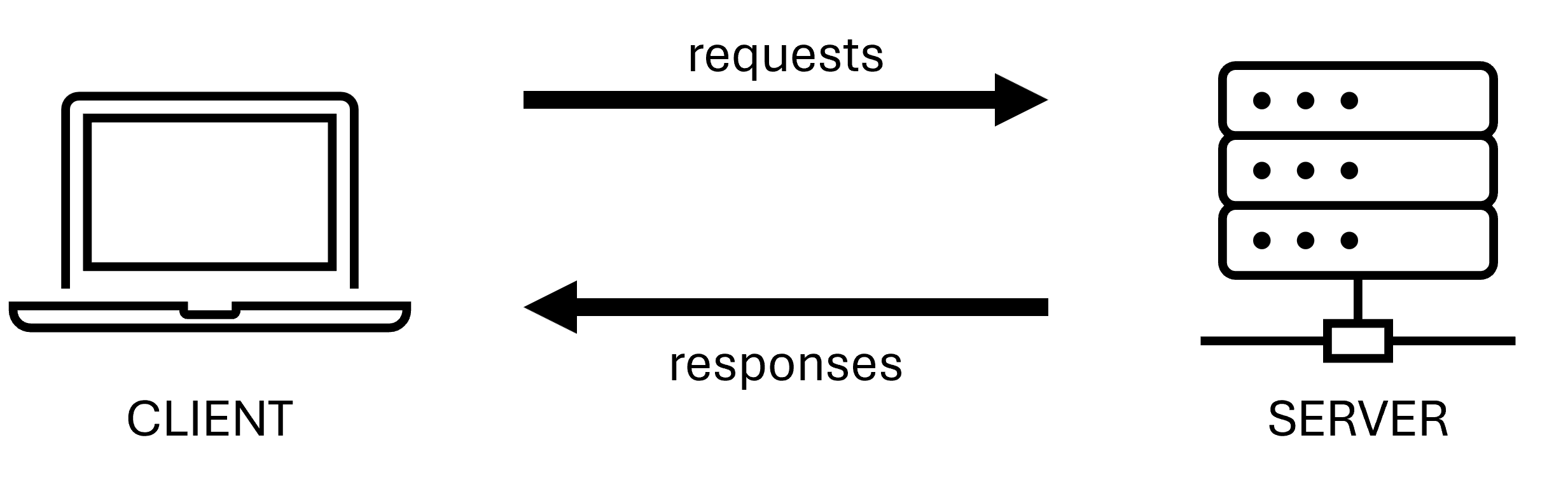
- GET
- HEAD
- POST
- PUT
- DELETE
- CONNECT
- OPTIONS
- TRACE
- PATCH
[3] GeeksforGeeks (2023). Types of Internet Protocols. Retrieved from https://www.geeksforgeeks.org/types-of-internet-protocols/"
[4] Mozilla (2023). HTTP request methods. Retrieved from https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods"
Luckily for us web scrapers, we do not need to memorize all nine types. Ninety nine percent of the time, we will only concern ourselves with GET and POST requests.
- "The GET method requests a representation of the specified resource. Requests using GET should only retrieve data."[5]
- "The POST method submits an entity to the specified resource, often causing a change in state or side effects on the server."[6]
Don't worry if you're confused. It's easy to tell which type you need to use. And today, we'll do a demo using both.
[5] Mozilla (2023). HTTP request methods. Retrieved from https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods"
[6] Ibid.
Accessing a website¶
When you enter a URL (e.g., www.brookings.edu) into your browser, several things happen:
- DNS lookup
- Initial HTTP request
- Server response
- Parsing HTML + additional requests
- Assembling the page
Step 1: DNS Lookup¶
Your browser first translates the human-readable URL (e.g. http://brookings.edu/) into an IP address (e.g. 137.135.107.235) using a Domain Name System (DNS) lookup.[7]
Think of the DNS search like the phone book that links a name of a store to a street address. The street address, in this case, is an IP address which points to the server where the website is hosted. [8] [9]
[7] Fun fact: we talked about internet protocols in the previous section, but only described HTTP, which is most relevant to this application. DNS is another type of internet protocol.
[8] Mozilla (2023). How the web works. Retrieved from https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web/How_the_Web_works
[9] Cloudflare. What is DNS? Retrieved from https://www.cloudflare.com/learning/dns/what-is-dns/
Step 2: HTTP Request¶
Now that your browser has the IP address of website, it sends an HTTP request to the server at this IP address. This request asks for the main HTML file of the website.
curl -X GET 'https://www.brookings.edu/' \
-H 'accept: text/html,application/xhtml+xml,application/xml;...' \
-H 'accept-language: en-US,en;q=0.9' \
-H 'cookie: _fbp=REDACTED; hubspotutk=REDACTED; ...' \
-H 'priority: u=0, i' \
-H 'referer: https://www.google.com/' \
-H 'sec-ch-ua: "Google Chrome";v="REDACTED", "Chromium";v="REDACTED", "Not.A/Brand";v="REDACTED"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "Windows"' \
-H 'sec-fetch-dest: document' \
-H 'sec-fetch-mode: navigate' \
-H 'sec-fetch-site: cross-site' \
-H 'sec-fetch-user: ?1' \
-H 'upgrade-insecure-requests: 1' \
-H 'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36'
Can you identify what type of request this is?
Step 3: Server Response¶
The server processes this request and sends back the requested HTML file. This file contains the basic structure of the webpage.
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0, viewport-fit=cover">
<meta name='robots' content='index, follow, max-image-preview:large, max-snippet:-1, max-video-preview:-1' />
<link rel="alternate" href="https://www.brookings.edu/" hreflang="en" />
<link rel="alternate" href="https://www.brookings.edu/es/" hreflang="es" />
<link rel="alternate" href="https://www.brookings.edu/ar/" hreflang="ar" />
<link rel="alternate" href="https://www.brookings.edu/zh/" hreflang="zh" />
<link rel="alternate" href="https://www.brookings.edu/fr/" hreflang="fr" />
<link rel="alternate" href="https://www.brookings.edu/ko/" hreflang="ko" />
<link rel="alternate" href="https://www.brookings.edu/ru/" hreflang="ru" />
<!-- This site is optimized with the Yoast SEO plugin v22.0 - https://yoast.com/wordpress/plugins/seo/ -->
<title>Brookings - Quality. Independence. Impact.</title>
<meta name="description" content="The Brookings Institution is a nonprofit public policy organization based in Washington, DC. Our mission is to conduct in-depth research that leads to new ideas for solving problems facing society at the local, national and global level." />
<link rel="canonical" href="https://www.brookings.edu/" />
<meta property="og:locale" content="en_US" />
Step 4: Parsing HTML + additional requests¶
Your browser starts parsing the HTML file: reading its instructions to turn it into a user-friendly webpage.
Oftentimes, this code contains references to additional external resources it needs to display the webpage, such as:
- CSS (Cascading Style Sheets): To set default aesthetics like fonts, colors, and line spacing
- JavaScript code: To add interactivity and dynamic content
- Images and videos: To incorporate multimedia content
- API (Application Programming Interface) responses: To obtain data from servers, often in JSON format, to display on the webpage
As your browser encounters additional references to files in the HTML code, it makes HTTP requests to the server to retrieve them.
Step 5: Assembling the page¶
After downloading all the external resources needed to build the webpage, your browser will compile and execute any JavaScript code that it received.
With all the downloaded elements in place, the browser processes the HTML, the CSS style sheets, and combines it with other resources (such as downloaded fonts, photos, videos, and data downloaded from APIs) to paint the webpage to your screen.[10]
[10] Mozilla (2023). Populating the page: how browsers work. Retrieved from https://developer.mozilla.org/en-US/docs/Web/Performance/How_browsers_work"
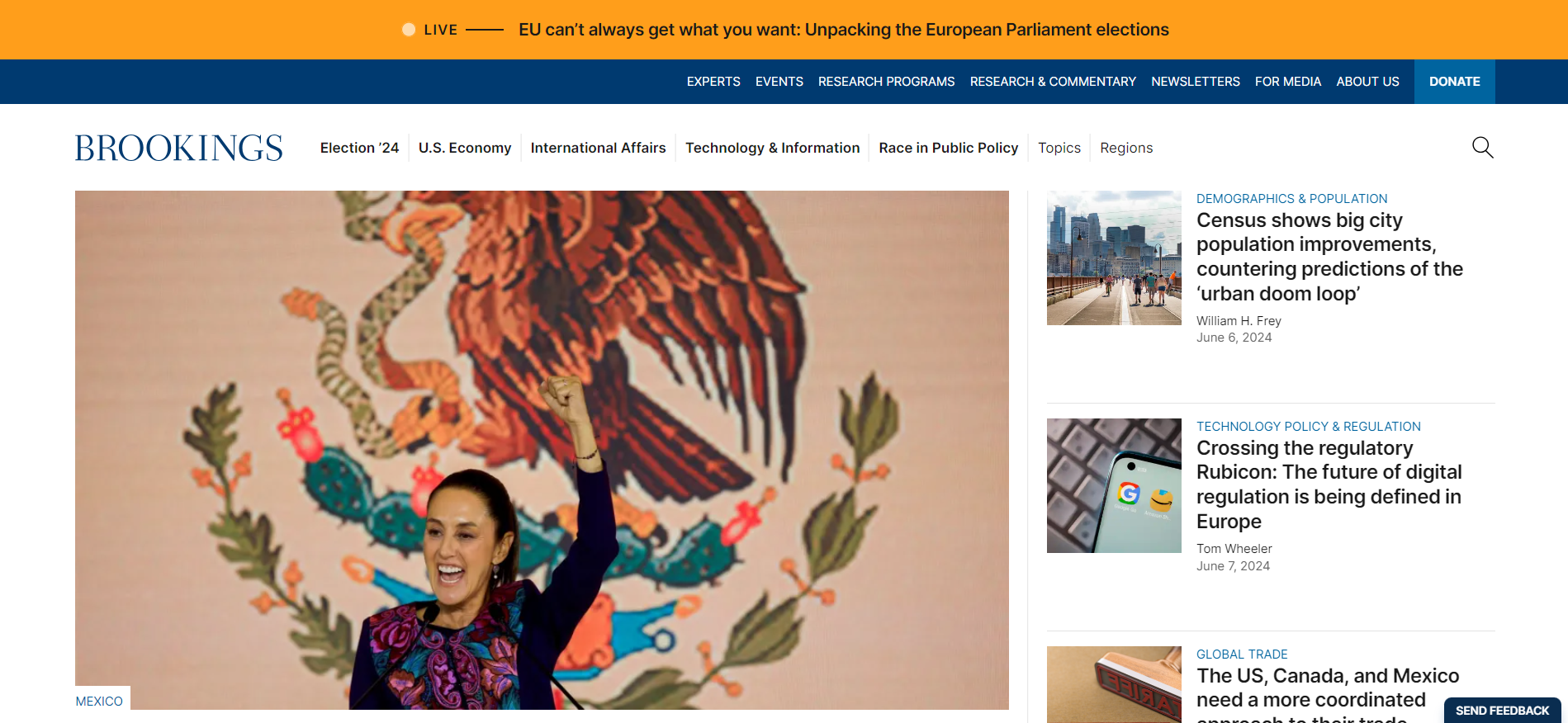
Web scraping basics¶
There are several ways to collect data online. The strategy you choose must be catered to the website in question.
Types of web scraping¶
I like to categorize web data collection techniques by the point in the client-server interaction that they interact.
- DNS lookup
- Initial HTTP request
- Server response
- HTML scraping parses the main HTML file for the webpage to extract data.
- Parsing HTML + additional requests
- Technically not classified as "web scraping," APIs are a neat way to access data. They are usually requested at this point in the client-server interaction.
- Assembling the page
- Selenium behaves like a browser to view content that is otherwise not available in HTML files, because it is dynamically rendered using JavaScript code.
Sample code: Web requests & HTML parsing¶
Knowing how to make HTTP requests using the Python requests library and parsing HTML responses are two foundational skills in our web scraping toolkit that will help us tackle more complicated tasks later.
pip install requests beautifulsoup4
Now that we've confirmed installation, we import the needed libraries.
import requests
from bs4 import BeautifulSoup
[11] It's a best practice to use environments to control package dependencies. This project uses Poetry: https://python-poetry.org/
Time to get scraping. Recall the earlier GET request we saw? It had a lot of information in it, in the form of headers.
curl -X GET 'https://www.brookings.edu/' \
-H 'accept: text/html,application/xhtml+xml,application/xml;...' \
-H 'accept-language: en-US,en;q=0.9' \
-H 'cookie: _fbp=REDACTED; hubspotutk=REDACTED; ...' \
-H 'priority: u=0, i' \
-H 'referer: https://www.google.com/' \
-H 'sec-ch-ua: "Google Chrome";v="REDACTED", "Chromium";v="REDACTED", "Not.A/Brand";v="REDACTED"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "Windows"' \
-H 'sec-fetch-dest: document' \
-H 'sec-fetch-mode: navigate' \
-H 'sec-fetch-site: cross-site' \
-H 'sec-fetch-user: ?1' \
-H 'upgrade-insecure-requests: 1' \
-H 'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36'
As you can see, headers contain quite a bit of information. Unless otherwise required, I try to keep my headers on the lighter side.
These are the headers I usually provide in my HTTP requests. Sometimes, I get blocked - in which case, I change the user-agent string slightly.
Note that headers must be formatted as a dictionary.
my_headers = {
'User-Agent': (
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/122.0.6261.112 Safari/537.36'
),
'Accept': (
'text/html,application/xhtml+xml,application/xml;q=0.9,'
'image/avif,image/webp,image/apng,*/*;q=0.8,'
'application/signed-exchange;v=b3;q=0.7'
)
}
Today, we'll be scraping a website that I created to practice on! Our URL is: https://lorae.github.io/web-scraping-tutorial/
my_url = "https://lorae.github.io/web-scraping-tutorial/"
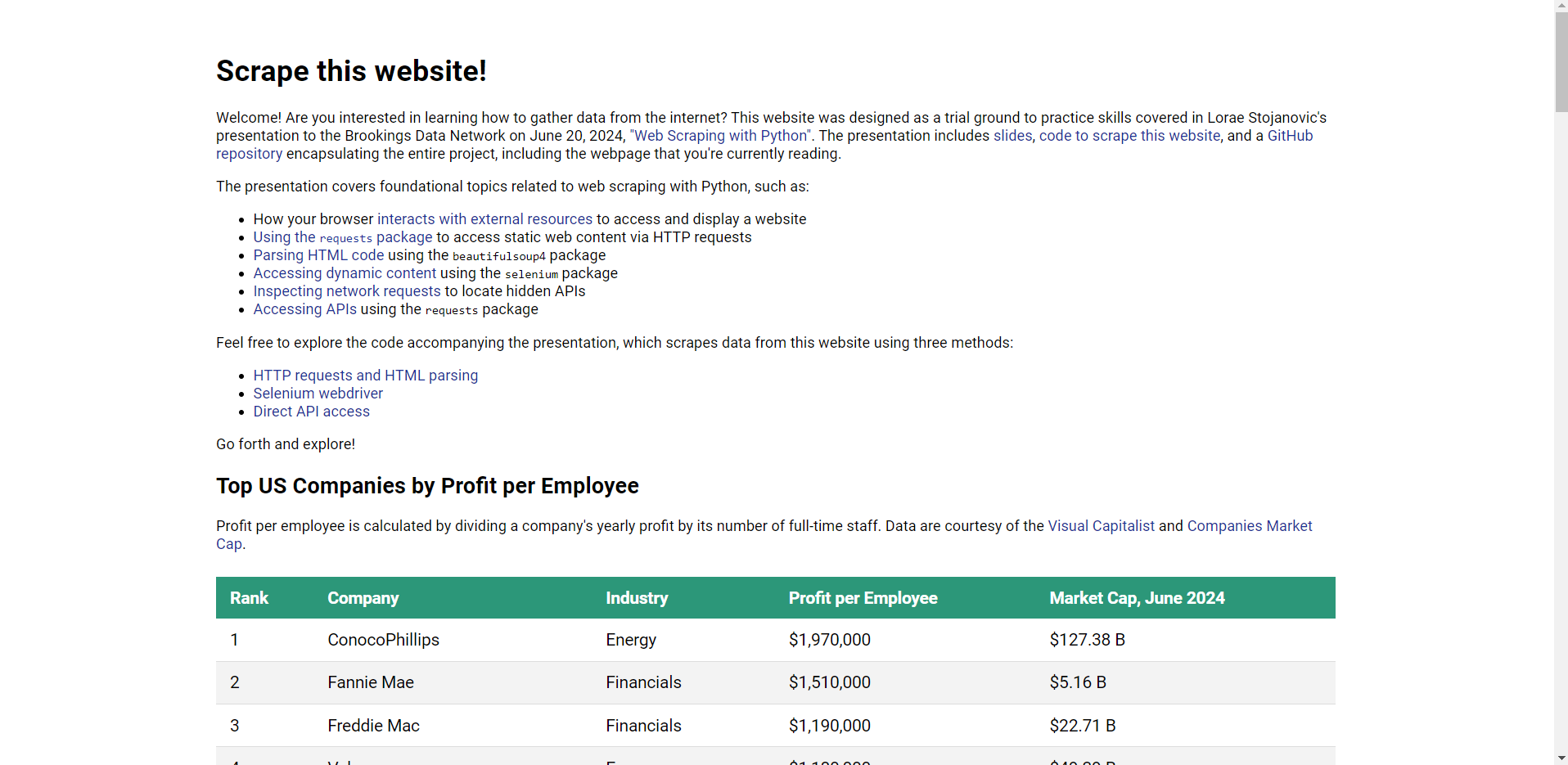
We're interested specifically in scraping the company names and profit per employee of the entries in the table in the webpage.
In order to do this, we have to first get the HTML file for the website.
In these next steps, we bundle our arguments together into an instance of the Request object from the requests library. We then initialize the session, prepare the request for sending, and save the response.
session_arguments = requests.Request(method='GET',
url=my_url,
headers=my_headers)
session = requests.Session()
prepared_request = session.prepare_request(session_arguments)
response: requests.Response = session.send(prepared_request)
Let's see what the response was. A response code of 200 indicates a successful response, with the server returning the required resource.
print(response.status_code)
200
Success!
More interestingly, let's look at the response content.
print(response.text)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Web Scraping Resources</title>
<link rel="stylesheet" href="web_content/css/styles.css">
<link href="https://fonts.googleapis.com/css2?family=Roboto:wght@400;700&display=swap" rel="stylesheet">
<script src="https://cdn.jsdelivr.net/npm/chart.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/PapaParse/5.3.0/papaparse.min.js"></script>
</head>
<body>
<div class="container">
<h1>Scrape this website!</h1>
<p>Welcome! Are you interested in learning how to gather data from the internet? This website was designed as a trial ground to practice skills covered in Lorae Stojanovic's presentation to the Brookings Data Network on June 20, 2024, <a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html">"Web Scraping with Python"</a>. The presentation includes <a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html">slides</a>, <a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html">code to scrape this website</a>, and a <a href="https://github.com/lorae/web-scraping-tutorial">GitHub repository</a> encapsulating the entire project, including the webpage that you're currently reading.</p>
<p>The presentation covers foundational topics related to web scraping with Python, such as:</p>
<ul>
<li>How your browser <a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html#/2/5">interacts with external resources</a> to access and display a website</li>
<li><a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html#/4/2">Using the <code>requests</code> package</a> to access static web content via HTTP requests</li>
<li><a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html#/4/9">Parsing HTML code</a> using the <code>beautifulsoup4</code> package</li>
<li><a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html#/5">Accessing dynamic content</a> using the <code>selenium</code> package</li>
<li><a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html#/6/1">Inspecting network requests</a> to locate hidden APIs</li>
<li><a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html#/6/10">Accessing APIs</a> using the <code>requests</code> package</li>
</ul>
<p>Feel free to explore the code accompanying the presentation, which scrapes data from this website using three methods:</p>
<ul>
<li><a href="#">HTTP requests and HTML parsing</a></li>
<li><a href="#">Selenium webdriver</a></li>
<li><a href="#">Direct API access</a></li>
</ul>
<p>Go forth and explore!</p>
<h2>Top US Companies by Profit per Employee</h2>
<p>Profit per employee is calculated by dividing a company's yearly profit by its number of full-time staff. Data are courtesy of the <a href="https://www.visualcapitalist.com/profit-per-employee-top-u-s-companies-ranking/">Visual Capitalist</a> and <a href="https://companiesmarketcap.com/">Companies Market Cap</a>.</p>
<table class="styled-table">
<thead>
<tr class="header-row">
<th class="header-cell rank">Rank</th>
<th class="header-cell company">Company</th>
<th class="header-cell industry">Industry</th>
<th class="header-cell profit-per-employee">Profit per Employee</th>
<th class="header-cell market-cap">Market Cap, June 2024</th>
</tr>
</thead>
<tbody>
<tr class="data-row">
<td class="data-cell rank">1</td>
<td class="data-cell company">ConocoPhillips</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$1,970,000</td>
<td class="data-cell market-cap">$127.38 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">2</td>
<td class="data-cell company">Fannie Mae</td>
<td class="data-cell industry">Financials</td>
<td class="data-cell profit-per-employee">$1,510,000</td>
<td class="data-cell market-cap">$5.16 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">3</td>
<td class="data-cell company">Freddie Mac</td>
<td class="data-cell industry">Financials</td>
<td class="data-cell profit-per-employee">$1,190,000</td>
<td class="data-cell market-cap">$22.71 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">4</td>
<td class="data-cell company">Valero</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$1,180,000</td>
<td class="data-cell market-cap">$49.39 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">5</td>
<td class="data-cell company">Occidental Petroleum</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$1,110,000</td>
<td class="data-cell market-cap">$54.31 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">6</td>
<td class="data-cell company">Cheniere Energy</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$921,000</td>
<td class="data-cell market-cap">$36.88 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">7</td>
<td class="data-cell company">ExxonMobil</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$899,000</td>
<td class="data-cell market-cap">$490.67 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">8</td>
<td class="data-cell company">Phillips 66</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$848,000</td>
<td class="data-cell market-cap">$57.59 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">9</td>
<td class="data-cell company">Marathon Petroleum</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$815,000</td>
<td class="data-cell market-cap">$60.75 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">10</td>
<td class="data-cell company">Chevron</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$809,000</td>
<td class="data-cell market-cap">$280.40 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">11</td>
<td class="data-cell company">PBF Energy</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$798,000</td>
<td class="data-cell market-cap">$5.10 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">12</td>
<td class="data-cell company">Enterprise Products</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$752,000</td>
<td class="data-cell market-cap">$61.45 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">13</td>
<td class="data-cell company">Apple</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$609,000</td>
<td class="data-cell market-cap">$3,245 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">14</td>
<td class="data-cell company">Broadcom</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$575,000</td>
<td class="data-cell market-cap">$839.05 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">15</td>
<td class="data-cell company">HF Sinclair</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$560,000</td>
<td class="data-cell market-cap">$10.01 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">16</td>
<td class="data-cell company">D. R. Horton</td>
<td class="data-cell industry">Construction</td>
<td class="data-cell profit-per-employee">$433,000</td>
<td class="data-cell market-cap">$45.90 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">17</td>
<td class="data-cell company">AIG</td>
<td class="data-cell industry">Financials</td>
<td class="data-cell profit-per-employee">$392,000</td>
<td class="data-cell market-cap">$49.19 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">18</td>
<td class="data-cell company">Lennar</td>
<td class="data-cell industry">Construction</td>
<td class="data-cell profit-per-employee">$384,000</td>
<td class="data-cell market-cap">$40.93 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">19</td>
<td class="data-cell company">Energy Transfer</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$379,000</td>
<td class="data-cell market-cap">$52.18 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">20</td>
<td class="data-cell company">Pfizer</td>
<td class="data-cell industry">Healthcare</td>
<td class="data-cell profit-per-employee">$378,000</td>
<td class="data-cell market-cap">$155.32 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">21</td>
<td class="data-cell company">Netflix</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$351,000</td>
<td class="data-cell market-cap">$295.45 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">22</td>
<td class="data-cell company">Microsoft</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$329,000</td>
<td class="data-cell market-cap">$3,317 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">23</td>
<td class="data-cell company">Alphabet</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$315,000</td>
<td class="data-cell market-cap">$2,170 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">24</td>
<td class="data-cell company">Meta</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$268,000</td>
<td class="data-cell market-cap">$1,266 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">25</td>
<td class="data-cell company">Qualcomm</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$254,000</td>
<td class="data-cell market-cap">$253.43 B</td>
</tr>
</tbody>
</table>
<h2>Learning resources</h2>
<div class="promo-grid__promos" id="resources-container">
<!-- Data will be populated here -->
</div>
</div>
<script>
let resourcesData = [];
async function fetchResources() {
const response = await fetch('web_content/data/web-scraping-resources.json');
resourcesData = await response.json();
displayResources(resourcesData);
}
function displayResources(data) {
const container = document.getElementById('resources-container');
container.innerHTML = '';
data.forEach(resource => {
const card = document.createElement('div');
card.className = 'digest-card';
const topSection = document.createElement('div');
topSection.className = 'digest-card__top';
const image = document.createElement('img');
image.className = 'digest-card__image';
image.src = resource.image;
image.alt = `${resource.title} image`;
topSection.appendChild(image);
const textContainer = document.createElement('div');
textContainer.className = 'digest-card__text';
const title = document.createElement('div');
title.className = 'digest-card__title';
title.innerHTML = `<a href="${resource.link}">${resource.title}</a>`;
textContainer.appendChild(title);
const date = document.createElement('div');
date.className = 'digest-card__date';
date.innerHTML = `<span class="digest-card__label">${resource.date}</span>`;
textContainer.appendChild(date);
const authors = document.createElement('div');
authors.className = 'digest-card__items';
authors.innerHTML = `<span class="digest-card__label">Author(s) - </span>${resource.authors.map(author => `<span><a href="${author.link}">${author.name}</a></span>`).join(', ')}`;
textContainer.appendChild(authors);
topSection.appendChild(textContainer);
card.appendChild(topSection);
const description = document.createElement('div');
description.className = 'digest-card__summary';
description.textContent = resource.description;
card.appendChild(description);
const keywords = document.createElement('div');
keywords.className = 'digest-card__keywords';
keywords.innerHTML = `<span class="digest-card__label">Keywords: </span>${resource.keywords.join(', ')}`;
card.appendChild(keywords);
container.appendChild(card);
});
}
fetchResources();
// Function to fetch and display GDP data
async function fetchGDPData() {
const response = await fetch('web_content/data/gdp-data.csv');
const data = await response.text();
const parsedData = Papa.parse(data, { header: true }).data;
const labels = parsedData.map(row => row.Date);
const gdpValues = parsedData.map(row => parseFloat(row.GDP));
const ctx = document.getElementById('gdpChart').getContext('2d');
new Chart(ctx, {
type: 'line',
data: {
labels: labels,
datasets: [{
label: 'US GDP',
data: gdpValues,
borderColor: 'rgba(75, 192, 192, 1)',
backgroundColor: 'rgba(75, 192, 192, 0.2)',
borderWidth: 1
}]
},
options: {
responsive: true,
scales: {
x: {
display: true,
title: {
display: true,
text: 'Year'
}
},
y: {
display: true,
title: {
display: true,
text: 'GDP (in billions)'
}
}
},
plugins: {
tooltip: {
enabled: true,
mode: 'nearest',
intersect: false,
callbacks: {
label: function(context) {
let label = context.dataset.label || '';
if (label) {
label += ': ';
}
if (context.parsed.y !== null) {
label += new Intl.NumberFormat('en-US', { style: 'currency', currency: 'USD' }).format(context.parsed.y);
}
return label;
}
}
}
}
}
});
}
fetchGDPData();
</script>
<div class = "container">
<h2>Interactive Graph</h2>
<p>The following graph contains United States nominal Gross Domestic Product data from Q1 1947 to Q1 2024. Data is courtesy of the Federal Reserve Bank of St. Louis "FRED" service. </p>
<div class="container">
<canvas id="gdpChart" width="400" height="200"></canvas>
</div>
</div>
</body>
</html>
HTML parsing with beautifulsoup4¶
The response from the website may look like a mess, but don't worry. There's a package that makes picking data from the HTML code easy: It's called beautifulsoup4. We'll use it in conjunction with a helpful browser tool called "Inspect element".
(And, later in this presentation, we'll use "View page source" and "Network requests": Two other old favorites.)
Simply right click anywhere on the website with your browser open, and select the "Inspect element" option.
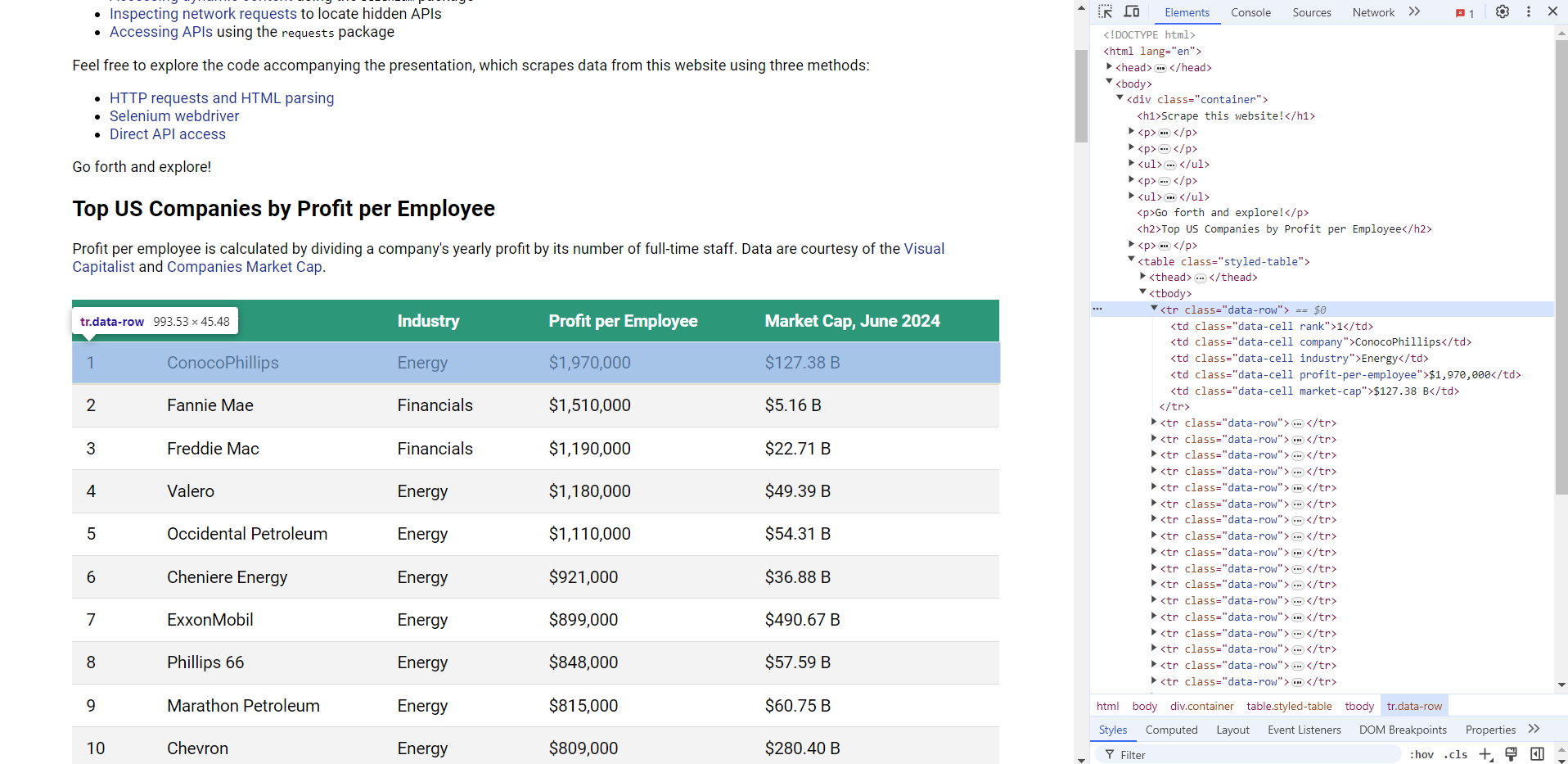
The data we want is contained in a <tr> element with class data-row. And after further inspection, we find that the company name is in a <td> child element with classes data-cell and company. The profit per employee is a sibling <td> element with classes data-cell and profit-per-employee.
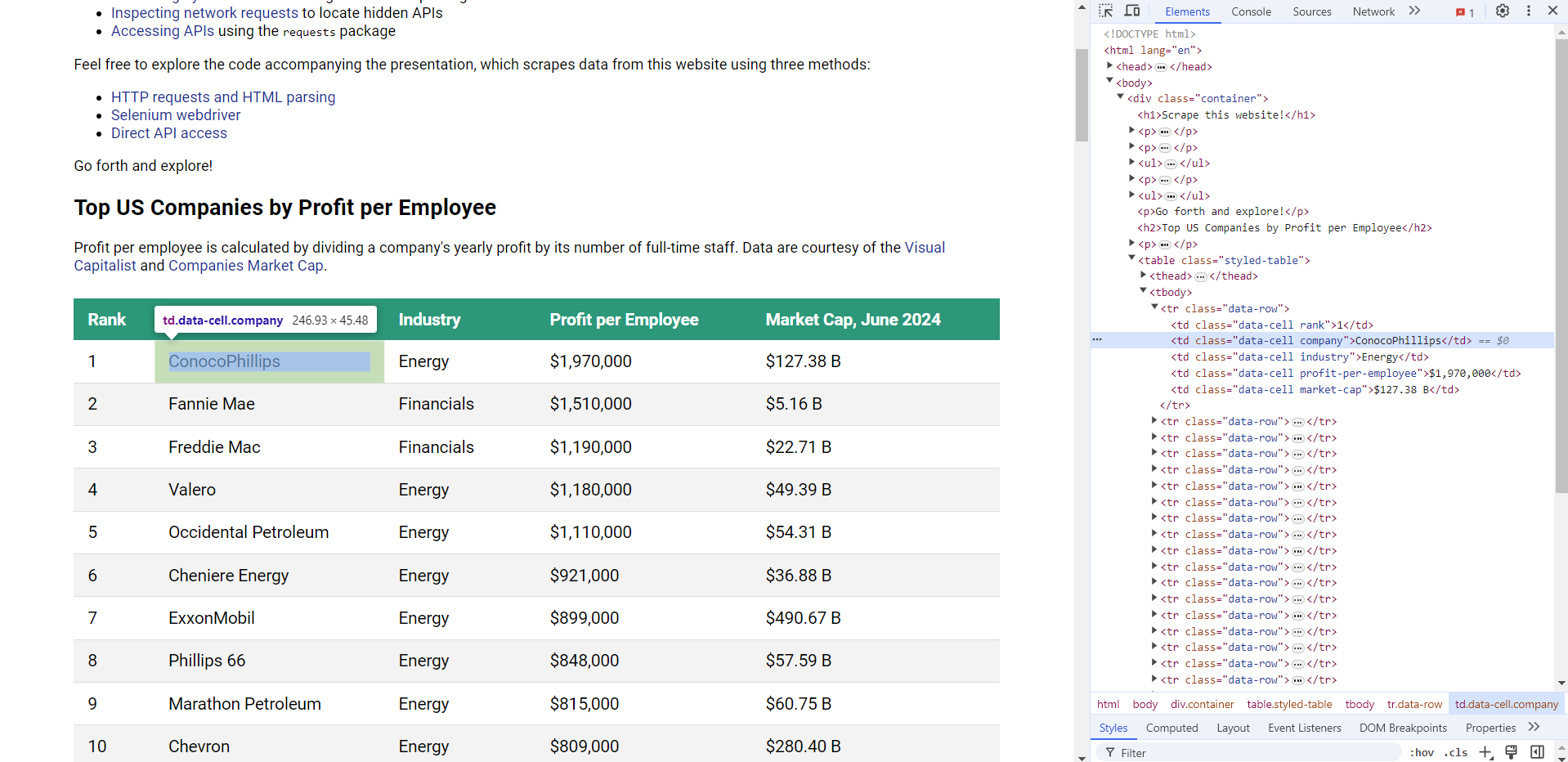
Let's parse the HTML of the response from the web server.
soup = BeautifulSoup(response.content, 'html.parser')
print(soup)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8"/>
<meta content="width=device-width, initial-scale=1.0" name="viewport"/>
<title>Web Scraping Resources</title>
<link href="web_content/css/styles.css" rel="stylesheet"/>
<link href="https://fonts.googleapis.com/css2?family=Roboto:wght@400;700&display=swap" rel="stylesheet"/>
<script src="https://cdn.jsdelivr.net/npm/chart.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/PapaParse/5.3.0/papaparse.min.js"></script>
</head>
<body>
<div class="container">
<h1>Scrape this website!</h1>
<p>Welcome! Are you interested in learning how to gather data from the internet? This website was designed as a trial ground to practice skills covered in Lorae Stojanovic's presentation to the Brookings Data Network on June 20, 2024, <a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html">"Web Scraping with Python"</a>. The presentation includes <a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html">slides</a>, <a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html">code to scrape this website</a>, and a <a href="https://github.com/lorae/web-scraping-tutorial">GitHub repository</a> encapsulating the entire project, including the webpage that you're currently reading.</p>
<p>The presentation covers foundational topics related to web scraping with Python, such as:</p>
<ul>
<li>How your browser <a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html#/2/5">interacts with external resources</a> to access and display a website</li>
<li><a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html#/4/2">Using the <code>requests</code> package</a> to access static web content via HTTP requests</li>
<li><a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html#/4/9">Parsing HTML code</a> using the <code>beautifulsoup4</code> package</li>
<li><a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html#/5">Accessing dynamic content</a> using the <code>selenium</code> package</li>
<li><a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html#/6/1">Inspecting network requests</a> to locate hidden APIs</li>
<li><a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html#/6/10">Accessing APIs</a> using the <code>requests</code> package</li>
</ul>
<p>Feel free to explore the code accompanying the presentation, which scrapes data from this website using three methods:</p>
<ul>
<li><a href="#">HTTP requests and HTML parsing</a></li>
<li><a href="#">Selenium webdriver</a></li>
<li><a href="#">Direct API access</a></li>
</ul>
<p>Go forth and explore!</p>
<h2>Top US Companies by Profit per Employee</h2>
<p>Profit per employee is calculated by dividing a company's yearly profit by its number of full-time staff. Data are courtesy of the <a href="https://www.visualcapitalist.com/profit-per-employee-top-u-s-companies-ranking/">Visual Capitalist</a> and <a href="https://companiesmarketcap.com/">Companies Market Cap</a>.</p>
<table class="styled-table">
<thead>
<tr class="header-row">
<th class="header-cell rank">Rank</th>
<th class="header-cell company">Company</th>
<th class="header-cell industry">Industry</th>
<th class="header-cell profit-per-employee">Profit per Employee</th>
<th class="header-cell market-cap">Market Cap, June 2024</th>
</tr>
</thead>
<tbody>
<tr class="data-row">
<td class="data-cell rank">1</td>
<td class="data-cell company">ConocoPhillips</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$1,970,000</td>
<td class="data-cell market-cap">$127.38 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">2</td>
<td class="data-cell company">Fannie Mae</td>
<td class="data-cell industry">Financials</td>
<td class="data-cell profit-per-employee">$1,510,000</td>
<td class="data-cell market-cap">$5.16 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">3</td>
<td class="data-cell company">Freddie Mac</td>
<td class="data-cell industry">Financials</td>
<td class="data-cell profit-per-employee">$1,190,000</td>
<td class="data-cell market-cap">$22.71 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">4</td>
<td class="data-cell company">Valero</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$1,180,000</td>
<td class="data-cell market-cap">$49.39 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">5</td>
<td class="data-cell company">Occidental Petroleum</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$1,110,000</td>
<td class="data-cell market-cap">$54.31 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">6</td>
<td class="data-cell company">Cheniere Energy</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$921,000</td>
<td class="data-cell market-cap">$36.88 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">7</td>
<td class="data-cell company">ExxonMobil</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$899,000</td>
<td class="data-cell market-cap">$490.67 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">8</td>
<td class="data-cell company">Phillips 66</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$848,000</td>
<td class="data-cell market-cap">$57.59 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">9</td>
<td class="data-cell company">Marathon Petroleum</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$815,000</td>
<td class="data-cell market-cap">$60.75 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">10</td>
<td class="data-cell company">Chevron</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$809,000</td>
<td class="data-cell market-cap">$280.40 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">11</td>
<td class="data-cell company">PBF Energy</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$798,000</td>
<td class="data-cell market-cap">$5.10 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">12</td>
<td class="data-cell company">Enterprise Products</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$752,000</td>
<td class="data-cell market-cap">$61.45 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">13</td>
<td class="data-cell company">Apple</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$609,000</td>
<td class="data-cell market-cap">$3,245 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">14</td>
<td class="data-cell company">Broadcom</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$575,000</td>
<td class="data-cell market-cap">$839.05 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">15</td>
<td class="data-cell company">HF Sinclair</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$560,000</td>
<td class="data-cell market-cap">$10.01 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">16</td>
<td class="data-cell company">D. R. Horton</td>
<td class="data-cell industry">Construction</td>
<td class="data-cell profit-per-employee">$433,000</td>
<td class="data-cell market-cap">$45.90 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">17</td>
<td class="data-cell company">AIG</td>
<td class="data-cell industry">Financials</td>
<td class="data-cell profit-per-employee">$392,000</td>
<td class="data-cell market-cap">$49.19 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">18</td>
<td class="data-cell company">Lennar</td>
<td class="data-cell industry">Construction</td>
<td class="data-cell profit-per-employee">$384,000</td>
<td class="data-cell market-cap">$40.93 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">19</td>
<td class="data-cell company">Energy Transfer</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$379,000</td>
<td class="data-cell market-cap">$52.18 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">20</td>
<td class="data-cell company">Pfizer</td>
<td class="data-cell industry">Healthcare</td>
<td class="data-cell profit-per-employee">$378,000</td>
<td class="data-cell market-cap">$155.32 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">21</td>
<td class="data-cell company">Netflix</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$351,000</td>
<td class="data-cell market-cap">$295.45 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">22</td>
<td class="data-cell company">Microsoft</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$329,000</td>
<td class="data-cell market-cap">$3,317 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">23</td>
<td class="data-cell company">Alphabet</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$315,000</td>
<td class="data-cell market-cap">$2,170 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">24</td>
<td class="data-cell company">Meta</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$268,000</td>
<td class="data-cell market-cap">$1,266 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">25</td>
<td class="data-cell company">Qualcomm</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$254,000</td>
<td class="data-cell market-cap">$253.43 B</td>
</tr>
</tbody>
</table>
<h2>Learning resources</h2>
<div class="promo-grid__promos" id="resources-container">
<!-- Data will be populated here -->
</div>
</div>
<script>
let resourcesData = [];
async function fetchResources() {
const response = await fetch('web_content/data/web-scraping-resources.json');
resourcesData = await response.json();
displayResources(resourcesData);
}
function displayResources(data) {
const container = document.getElementById('resources-container');
container.innerHTML = '';
data.forEach(resource => {
const card = document.createElement('div');
card.className = 'digest-card';
const topSection = document.createElement('div');
topSection.className = 'digest-card__top';
const image = document.createElement('img');
image.className = 'digest-card__image';
image.src = resource.image;
image.alt = `${resource.title} image`;
topSection.appendChild(image);
const textContainer = document.createElement('div');
textContainer.className = 'digest-card__text';
const title = document.createElement('div');
title.className = 'digest-card__title';
title.innerHTML = `<a href="${resource.link}">${resource.title}</a>`;
textContainer.appendChild(title);
const date = document.createElement('div');
date.className = 'digest-card__date';
date.innerHTML = `<span class="digest-card__label">${resource.date}</span>`;
textContainer.appendChild(date);
const authors = document.createElement('div');
authors.className = 'digest-card__items';
authors.innerHTML = `<span class="digest-card__label">Author(s) - </span>${resource.authors.map(author => `<span><a href="${author.link}">${author.name}</a></span>`).join(', ')}`;
textContainer.appendChild(authors);
topSection.appendChild(textContainer);
card.appendChild(topSection);
const description = document.createElement('div');
description.className = 'digest-card__summary';
description.textContent = resource.description;
card.appendChild(description);
const keywords = document.createElement('div');
keywords.className = 'digest-card__keywords';
keywords.innerHTML = `<span class="digest-card__label">Keywords: </span>${resource.keywords.join(', ')}`;
card.appendChild(keywords);
container.appendChild(card);
});
}
fetchResources();
// Function to fetch and display GDP data
async function fetchGDPData() {
const response = await fetch('web_content/data/gdp-data.csv');
const data = await response.text();
const parsedData = Papa.parse(data, { header: true }).data;
const labels = parsedData.map(row => row.Date);
const gdpValues = parsedData.map(row => parseFloat(row.GDP));
const ctx = document.getElementById('gdpChart').getContext('2d');
new Chart(ctx, {
type: 'line',
data: {
labels: labels,
datasets: [{
label: 'US GDP',
data: gdpValues,
borderColor: 'rgba(75, 192, 192, 1)',
backgroundColor: 'rgba(75, 192, 192, 0.2)',
borderWidth: 1
}]
},
options: {
responsive: true,
scales: {
x: {
display: true,
title: {
display: true,
text: 'Year'
}
},
y: {
display: true,
title: {
display: true,
text: 'GDP (in billions)'
}
}
},
plugins: {
tooltip: {
enabled: true,
mode: 'nearest',
intersect: false,
callbacks: {
label: function(context) {
let label = context.dataset.label || '';
if (label) {
label += ': ';
}
if (context.parsed.y !== null) {
label += new Intl.NumberFormat('en-US', { style: 'currency', currency: 'USD' }).format(context.parsed.y);
}
return label;
}
}
}
}
}
});
}
fetchGDPData();
</script>
<div class="container">
<h2>Interactive Graph</h2>
<p>The following graph contains United States nominal Gross Domestic Product data from Q1 1947 to Q1 2024. Data is courtesy of the Federal Reserve Bank of St. Louis "FRED" service. </p>
<div class="container">
<canvas height="200" id="gdpChart" width="400"></canvas>
</div>
</div>
</body>
</html>
Once it's a BeautifulSoup object, it's pretty easy to get the data you want. The key is selecting the right elements using the correct tags.
We'll use for loops for this.
# Select elements corresponding to table rows
elements = soup.select('tr.data-row')
# Initialize lists for data output
Companies = []
PPEs = []
for el in elements:
company = el.find('td', class_='company').text
ppe = el.find('td', class_='profit-per-employee').text
# Add data to lists
Companies.append(company)
PPEs.append(ppe)
print(Companies)
print(PPEs)
['ConocoPhillips', 'Fannie Mae', 'Freddie Mac', 'Valero', 'Occidental Petroleum', 'Cheniere Energy', 'ExxonMobil', 'Phillips 66', 'Marathon Petroleum', 'Chevron', 'PBF Energy', 'Enterprise Products', 'Apple', 'Broadcom', 'HF Sinclair', 'D. R. Horton', 'AIG', 'Lennar', 'Energy Transfer', 'Pfizer', 'Netflix', 'Microsoft', 'Alphabet', 'Meta', 'Qualcomm'] ['$1,970,000', '$1,510,000', '$1,190,000', '$1,180,000', '$1,110,000', '$921,000', '$899,000', '$848,000', '$815,000', '$809,000', '$798,000', '$752,000', '$609,000', '$575,000', '$560,000', '$433,000', '$392,000', '$384,000', '$379,000', '$378,000', '$351,000', '$329,000', '$315,000', '$268,000', '$254,000']
Wow, we're pros! Should we try another one? Let's get titles and links of learning resources listed on the website. First we inspect element to find the element and class:
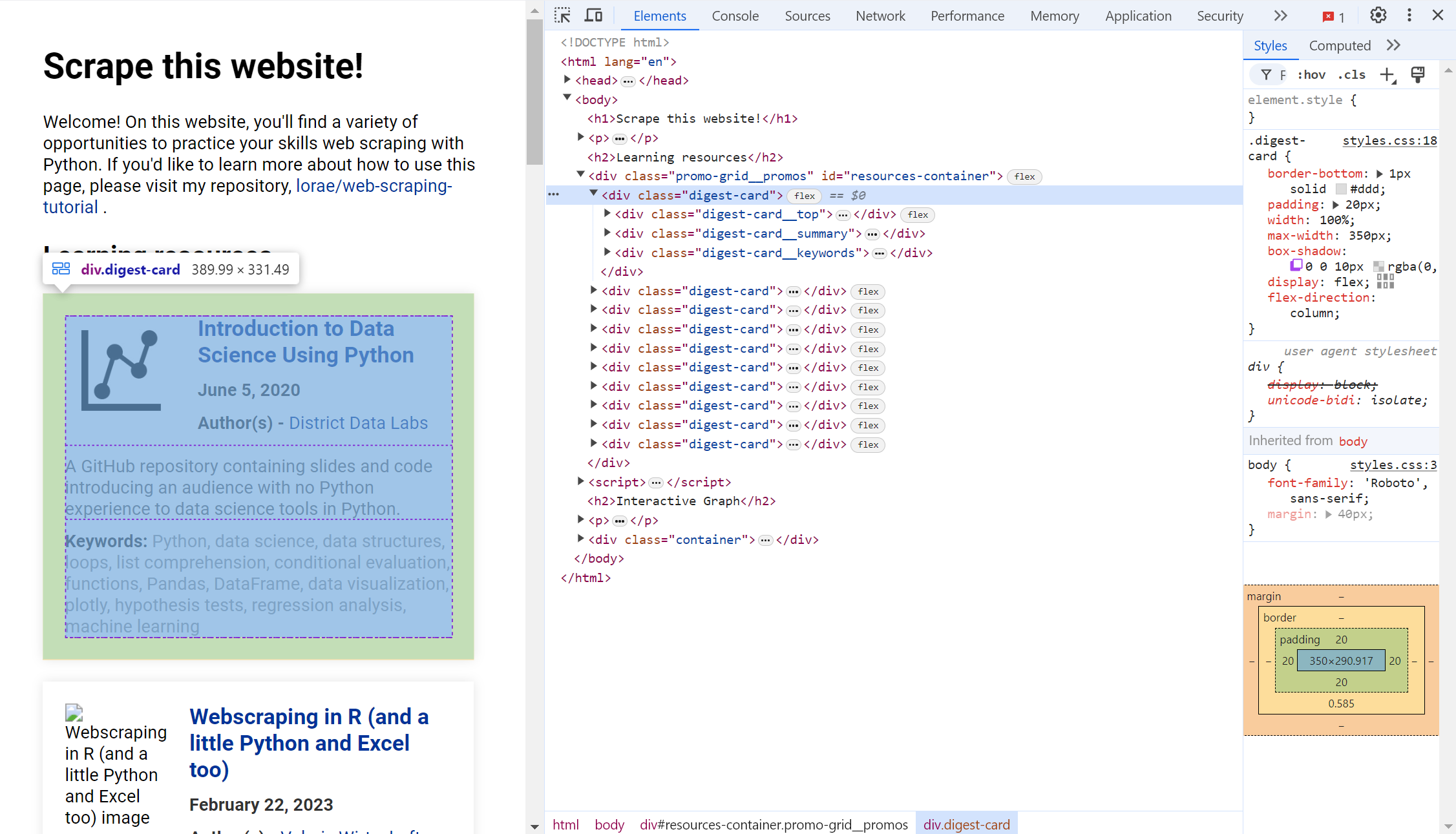
Data on web scraping learning resources are continained in a <div> element with class digest-card. The title of the resource is in a child <div> element with class digest-card__title: more specifically, the text is stored in an <a> element, with the hyperlink stored in the href attribute.
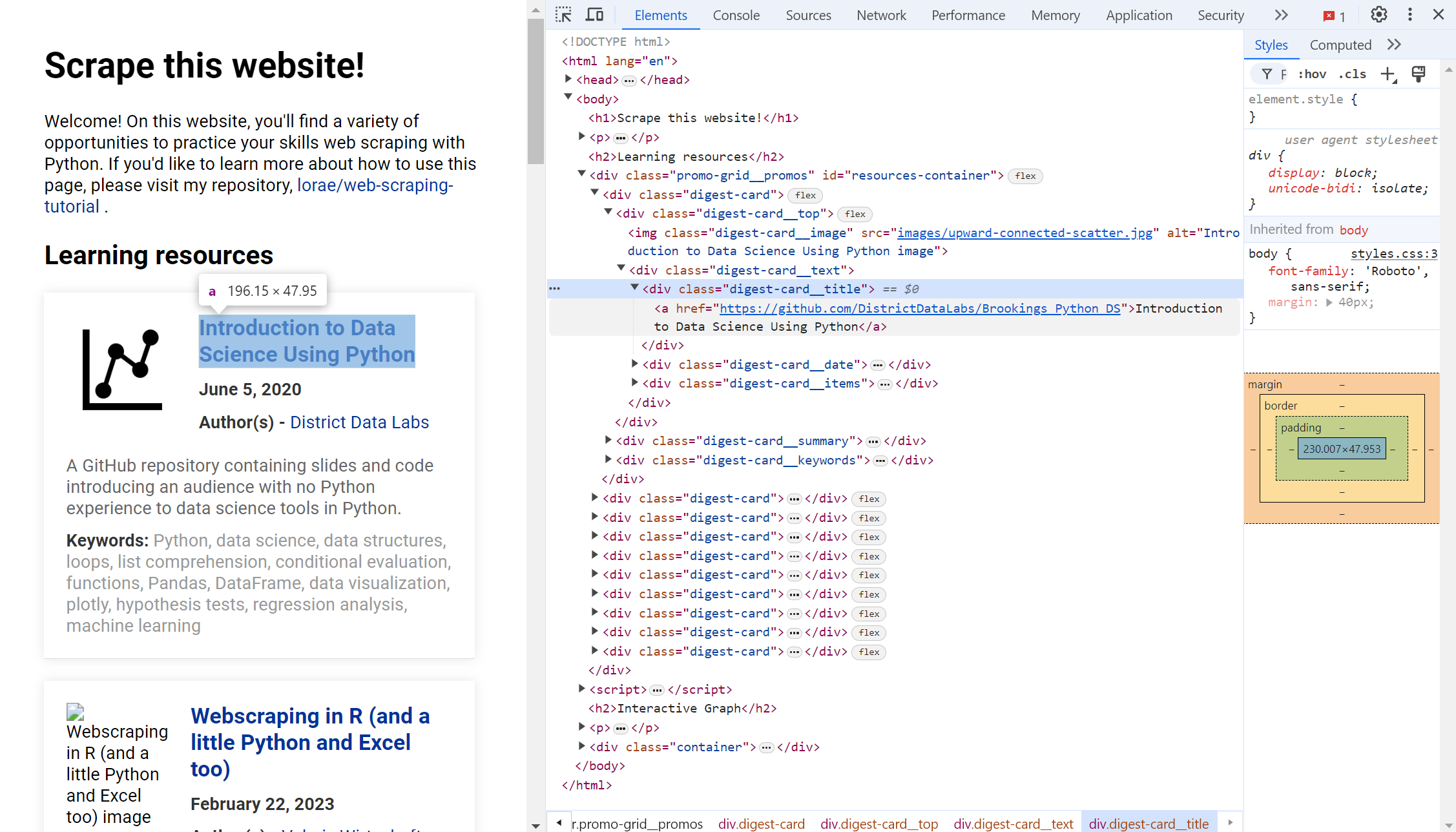
# Scrape titles and links
elements = soup.select('div.digest-card__title a')
# Initialize lists
Titles = []
Links = []
for el in elements:
print(el)
# Obtain the link to the resource
link = el['href'] # 'href' is a HTML lingo for hyperlinks.
# Obtain the title of the resource
title = el.text
# Append the entries to each list
Titles.append(title)
Links.append(link)
# Print the results
print(Titles)
print(Links)
[] []
Why didn't this work?
This part of the webpage is rendered using JavaScript! This is becoming an increasingly common occurence on today's web, which is why pure HTML scraping is becoming less and less feasible.
How do you know JavaScript is the culprit?
- Your code has no syntax errors yet doesn't pick up elements from the HTML code
- "View page source" shows no hard-coded elements
- "Network requests" reveal the JavaScript files used to populate the page
Sample code: selenium¶
selenium is a tool in Python (and many other programming languages) that allows users to access dynamic web content by automating web browser interactions.[12]
It simulates a real user browsing the web, which enables it to capture JavaScript-rendered content and other dynamic elements that one-off HTTP requests cannot access.
[12] Selenium documentation can be found here: https://www.selenium.dev/documentation/webdriver/getting_started/
But first, a note...¶
Selenium is just a tool to get an HTML file. Once you obtain the file, you parse it exactly the same way as we did in the previous section: using a tool of choice, like Beautiful Soup.
Let's start by importing the needed modules.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup
selenium can run on many browsers, like Chrome and Firefox. For simplicity, we will use Chrome today.
In order for the code to work, you must have Chrome installed on your computer.
# Set up Chrome options
chrome_options = Options()
chrome_options.add_argument("--headless")
If you don't turn on "headless" mode, your browser will pop up on your screen when you run the code.
# Set up Chrome driver
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options)
# Open the website
url = "https://lorae.github.io/web-scraping-tutorial/"
driver.get(url)
# Get the HTML content of the page
html_content = driver.page_source
print(html_content)
<html lang="en"><head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Web Scraping Resources</title>
<link rel="stylesheet" href="web_content/css/styles.css">
<link href="https://fonts.googleapis.com/css2?family=Roboto:wght@400;700&display=swap" rel="stylesheet">
<script src="https://cdn.jsdelivr.net/npm/chart.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/PapaParse/5.3.0/papaparse.min.js"></script>
</head>
<body>
<div class="container">
<h1>Scrape this website!</h1>
<p>Welcome! Are you interested in learning how to gather data from the internet? This website was designed as a trial ground to practice skills covered in Lorae Stojanovic's presentation to the Brookings Data Network on June 20, 2024, <a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html">"Web Scraping with Python"</a>. The presentation includes <a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html">slides</a>, <a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html">code to scrape this website</a>, and a <a href="https://github.com/lorae/web-scraping-tutorial">GitHub repository</a> encapsulating the entire project, including the webpage that you're currently reading.</p>
<p>The presentation covers foundational topics related to web scraping with Python, such as:</p>
<ul>
<li>How your browser <a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html#/2/5">interacts with external resources</a> to access and display a website</li>
<li><a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html#/4/2">Using the <code>requests</code> package</a> to access static web content via HTTP requests</li>
<li><a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html#/4/9">Parsing HTML code</a> using the <code>beautifulsoup4</code> package</li>
<li><a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html#/5">Accessing dynamic content</a> using the <code>selenium</code> package</li>
<li><a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html#/6/1">Inspecting network requests</a> to locate hidden APIs</li>
<li><a href="https://lorae.github.io/web-scraping-tutorial/advanced-web-scraping.slides.html#/6/10">Accessing APIs</a> using the <code>requests</code> package</li>
</ul>
<p>Feel free to explore the code accompanying the presentation, which scrapes data from this website using three methods:</p>
<ul>
<li><a href="#">HTTP requests and HTML parsing</a></li>
<li><a href="#">Selenium webdriver</a></li>
<li><a href="#">Direct API access</a></li>
</ul>
<p>Go forth and explore!</p>
<h2>Top US Companies by Profit per Employee</h2>
<p>Profit per employee is calculated by dividing a company's yearly profit by its number of full-time staff. Data are courtesy of the <a href="https://www.visualcapitalist.com/profit-per-employee-top-u-s-companies-ranking/">Visual Capitalist</a> and <a href="https://companiesmarketcap.com/">Companies Market Cap</a>.</p>
<table class="styled-table">
<thead>
<tr class="header-row">
<th class="header-cell rank">Rank</th>
<th class="header-cell company">Company</th>
<th class="header-cell industry">Industry</th>
<th class="header-cell profit-per-employee">Profit per Employee</th>
<th class="header-cell market-cap">Market Cap, June 2024</th>
</tr>
</thead>
<tbody>
<tr class="data-row">
<td class="data-cell rank">1</td>
<td class="data-cell company">ConocoPhillips</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$1,970,000</td>
<td class="data-cell market-cap">$127.38 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">2</td>
<td class="data-cell company">Fannie Mae</td>
<td class="data-cell industry">Financials</td>
<td class="data-cell profit-per-employee">$1,510,000</td>
<td class="data-cell market-cap">$5.16 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">3</td>
<td class="data-cell company">Freddie Mac</td>
<td class="data-cell industry">Financials</td>
<td class="data-cell profit-per-employee">$1,190,000</td>
<td class="data-cell market-cap">$22.71 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">4</td>
<td class="data-cell company">Valero</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$1,180,000</td>
<td class="data-cell market-cap">$49.39 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">5</td>
<td class="data-cell company">Occidental Petroleum</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$1,110,000</td>
<td class="data-cell market-cap">$54.31 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">6</td>
<td class="data-cell company">Cheniere Energy</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$921,000</td>
<td class="data-cell market-cap">$36.88 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">7</td>
<td class="data-cell company">ExxonMobil</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$899,000</td>
<td class="data-cell market-cap">$490.67 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">8</td>
<td class="data-cell company">Phillips 66</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$848,000</td>
<td class="data-cell market-cap">$57.59 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">9</td>
<td class="data-cell company">Marathon Petroleum</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$815,000</td>
<td class="data-cell market-cap">$60.75 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">10</td>
<td class="data-cell company">Chevron</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$809,000</td>
<td class="data-cell market-cap">$280.40 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">11</td>
<td class="data-cell company">PBF Energy</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$798,000</td>
<td class="data-cell market-cap">$5.10 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">12</td>
<td class="data-cell company">Enterprise Products</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$752,000</td>
<td class="data-cell market-cap">$61.45 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">13</td>
<td class="data-cell company">Apple</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$609,000</td>
<td class="data-cell market-cap">$3,245 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">14</td>
<td class="data-cell company">Broadcom</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$575,000</td>
<td class="data-cell market-cap">$839.05 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">15</td>
<td class="data-cell company">HF Sinclair</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$560,000</td>
<td class="data-cell market-cap">$10.01 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">16</td>
<td class="data-cell company">D. R. Horton</td>
<td class="data-cell industry">Construction</td>
<td class="data-cell profit-per-employee">$433,000</td>
<td class="data-cell market-cap">$45.90 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">17</td>
<td class="data-cell company">AIG</td>
<td class="data-cell industry">Financials</td>
<td class="data-cell profit-per-employee">$392,000</td>
<td class="data-cell market-cap">$49.19 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">18</td>
<td class="data-cell company">Lennar</td>
<td class="data-cell industry">Construction</td>
<td class="data-cell profit-per-employee">$384,000</td>
<td class="data-cell market-cap">$40.93 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">19</td>
<td class="data-cell company">Energy Transfer</td>
<td class="data-cell industry">Energy</td>
<td class="data-cell profit-per-employee">$379,000</td>
<td class="data-cell market-cap">$52.18 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">20</td>
<td class="data-cell company">Pfizer</td>
<td class="data-cell industry">Healthcare</td>
<td class="data-cell profit-per-employee">$378,000</td>
<td class="data-cell market-cap">$155.32 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">21</td>
<td class="data-cell company">Netflix</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$351,000</td>
<td class="data-cell market-cap">$295.45 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">22</td>
<td class="data-cell company">Microsoft</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$329,000</td>
<td class="data-cell market-cap">$3,317 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">23</td>
<td class="data-cell company">Alphabet</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$315,000</td>
<td class="data-cell market-cap">$2,170 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">24</td>
<td class="data-cell company">Meta</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$268,000</td>
<td class="data-cell market-cap">$1,266 B</td>
</tr>
<tr class="data-row">
<td class="data-cell rank">25</td>
<td class="data-cell company">Qualcomm</td>
<td class="data-cell industry">Tech</td>
<td class="data-cell profit-per-employee">$254,000</td>
<td class="data-cell market-cap">$253.43 B</td>
</tr>
</tbody>
</table>
<h2>Learning resources</h2>
<div class="promo-grid__promos" id="resources-container"><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/upward-connected-scatter.jpg" alt="Introduction to Data Science Using Python image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://github.com/DistrictDataLabs/Brookings_Python_DS">Introduction to Data Science Using Python</a></div><div class="digest-card__date"><span class="digest-card__label">June 5, 2020</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://districtdatalabs.silvrback.com/">District Data Labs</a></span></div></div></div><div class="digest-card__summary">A GitHub repository containing slides and code introducing an audience with no Python experience to data science tools in Python.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>Python, data science, data structures, loops, list comprehension, conditional evaluation, functions, Pandas, DataFrames, data visualization, plotly, hypothesis tests, regression analysis, machine learning</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/document.jpg" alt="Webscraping in R (and a little Python and Excel too) image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://example.com/secret">Webscraping in R (and a little Python and Excel too)</a></div><div class="digest-card__date"><span class="digest-card__label">February 22, 2023</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="#">Valerie Wirtschafter</a></span>, <span><a href="#">Mimi Majumder</a></span></div></div></div><div class="digest-card__summary">A thorough introductory guide to web scraping for R users, suitable for an absolute beginner. Explains using CSS selectors, scheduling jobs, and scraping tables, images, and PDFs, among other topics.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>copy-paste, APIs, DOM parsing, HTML, CSS, polite, rvest, paginated webpages, cronR, pdftools, requests, BeautifulSoup, Excel</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/laptop-web.jpg" alt="Populating the page: how browsers work image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://developer.mozilla.org/en-US/docs/Web/Performance/How_browsers_work">Populating the page: how browsers work</a></div><div class="digest-card__date"><span class="digest-card__label">July 20, 2023</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://developer.mozilla.org/en-US/docs/Web/Performance/How_browsers_work/contributors.txt">MDN contributors</a></span></div></div></div><div class="digest-card__summary">A concise blog post, aimed at developers, that explains how browsers provide their users with a web experience.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>DNS lookup, TCP handshake, TLS negotiation, HTTP GET request, response, parsing, DOM tree, CSSOM tree, JavaScript compilation, render, paint</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/router.jpg" alt="What is DNS? | How DNS works image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://www.cloudflare.com/learning/dns/what-is-dns/">What is DNS? | How DNS works</a></div><div class="digest-card__date"><span class="digest-card__label"></span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="#"></a></span></div></div></div><div class="digest-card__summary">A blog post explaining the DNS resolution process. A useful starting point for laypeople interested in learning more about the process.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>DNS server, IP address, recursive DNS resolver, DNS lookup, DNS caching</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/writing-website-with-image.jpg" alt="How the web works image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web/How_the_Web_works">How the web works</a></div><div class="digest-card__date"><span class="digest-card__label">November 17, 2023</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web/How_the_Web_works/contributors.txt">MDN contributors</a></span></div></div></div><div class="digest-card__summary">A high-level blog post accessible to beginners, aimed at developers, that explains how a phone or computer browser displays a webpage. Part of a longer series of blog posts that may be helpful for those hoping to learn more about browsers in depth.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>clients, servers, requests, responses, TCP, IP address, DNS, HTTP, component files, code files, assets, packets</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/computer.jpg" alt="A Practical Introduction to Web Scraping in Python image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://realpython.com/python-web-scraping-practical-introduction/">A Practical Introduction to Web Scraping in Python</a></div><div class="digest-card__date"><span class="digest-card__label"></span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://realpython.com/python-web-scraping-practical-introduction/#author">David Amos</a></span></div></div></div><div class="digest-card__summary">A tutorial aimed at beginners to web scraping with some prior knowledge of Python. Focuses mainly on building skills with HTML parsing using BeautifulSoup and interacting with the browser using MechanicalSoup. After this tutorial, users will likely be ready to learn to use Selenium.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>HTML, regex, regular expressions, BeautifulSoup, MechanicalSoup</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/book.jpg" alt="Automate the Boring Stuff: Web Scraping (Chapter 12) image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://automatetheboringstuff.com/2e/chapter12/">Automate the Boring Stuff: Web Scraping (Chapter 12)</a></div><div class="digest-card__date"><span class="digest-card__label"></span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://realpython.com/python-web-scraping-practical-introduction/#author">Al Sweigart</a></span></div></div></div><div class="digest-card__summary">A free online textbook introducing users to concepts in Python. This chapter assumes basic proficiency in Python from reading previous chapters. Walks users through inspecting the HTML code underlying websites using developer tools on the web browser, parsing the content using BeautifulSoup, and rendering interactive pages using a Selenium webdriver.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>requests, GET requests, HTML, View page source, Inspect element, Developer tools, HTML elements, BeautifulSoup, select method, Selenium</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/laptop-web.jpg" alt="Getting Started (with Selenium) image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://www.selenium.dev/documentation/webdriver/getting_started/">Getting Started (with Selenium)</a></div><div class="digest-card__date"><span class="digest-card__label">January 12, 2022</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="#"></a></span></div></div></div><div class="digest-card__summary">Generalized documentation for Selenium using multiple programming languages (like Python), including installing the library and organizing and executing Selenium code. Includes several lines of sample code illustrating how to start and end a session, find elements, and take action on elements.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>webdrivers, browsers, waits, elements, interactions, sample code, Python</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/building-blocks.jpg" alt="Getting started with the web image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web">Getting started with the web</a></div><div class="digest-card__date"><span class="digest-card__label">February 4, 2024</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web/contributors.txt">MDN contributors</a></span></div></div></div><div class="digest-card__summary">A high-quality series of blog posts that guides skills levels ranging from absolute beginners to those with more intermediate understanding through the process of building a website. Comprised of short, accessible blog posts covering many topics, including how the web works, and introductions to HTML, CSS, and JavaScript. Aimed at developers, but serves as useful background for more general audiences and those interested in understanding the web better for web scraping.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>HTML, CSS, JavaScript, tools and testing</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/single-page-file.jpg" alt="roundup image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web">roundup</a></div><div class="digest-card__date"><span class="digest-card__label">June 16, 2024</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="#">Lorae Stojanovic</a></span></div></div></div><div class="digest-card__summary">Lorae's (the creater of this website) GitHub repository which scrapes pre-print academic economics papers from 20+ sources; presents titles, abstracts, authors and hyperlinks on an online dashboard. Auto-updates daily using GitHub Actions workflow. May be helpful sample code for those interested in web scraping in Python or automating their scraping using GitHub Actions.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>web scraping, Python, GitHub Actions, Streamlit</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/chat-box.jpg" alt="Text Mining with R: A Tidy Approach image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://www.tidytextmining.com/">Text Mining with R: A Tidy Approach</a></div><div class="digest-card__date"><span class="digest-card__label">2023</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://juliasilge.com/">Julia Silge</a></span>, <span><a href="http://varianceexplained.org/">David Robinson</a></span></div></div></div><div class="digest-card__summary">A free, open-source book by the authors of the `tidytext` R package that introduces text mining in R. The authors provide extensive examples of text analysis in action, including sentiment analysis, the tf-idf statistic, n-grams, and document-term matrics. Real examples use data from Twitter archives, NASA datasets, and more.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>tidytext, unnest_tokens(), sentiments dataset, tf-idf statistic, n-grams, document-term matrices, tidy() method</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/chat-box.jpg" alt="Text as Data image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://cbail.github.io/textasdata/Text_as_Data.html">Text as Data</a></div><div class="digest-card__date"><span class="digest-card__label">2023</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://www.chrisbail.net/">Chris Bail</a></span></div></div></div><div class="digest-card__summary">A free, online course by a Professor of Sociology, Public Policy, and Data Science at Duke University. The course materials - which involve programming in R - are available on his GitHub page. His course covers topics such as APIs, basic text analysis, dictionary-based text analysis, topic modeling, text networks, and word embeddings.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>GitHub, text as data, screen-scraping, APIs, basic text analysis, dictionary-based text analysis, topic modeling, text networks, word embeddings</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/newspaper.jpg" alt="Text as Data (Spring 2021, NYU) image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://github.com/ArthurSpirling/text-as-data-class-spring2021">Text as Data (Spring 2021, NYU)</a></div><div class="digest-card__date"><span class="digest-card__label">January 8, 2021</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://github.com/ArthurSpirling">Arthur Sprling</a></span></div></div></div><div class="digest-card__summary">An NYU course taught in spring 2021, aimed at students who have taken at least one class in statistics or inference and who have a basic knowledge of calculus, progability, densities, distributions, statistical tests, hypothesis testing, maximum likelihood, and generalized linear models. The course is applied and uses R as a programming language.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>GitHub, vector space model of a document, bag of words, word distributions, lexical diversity, sentiment, machine learning, support vector machines, k-NN models, random forests/trees, bursts and memes</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/newspaper.jpg" alt="Web Scraping with R image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://steviep42.github.io/webscraping/book">Web Scraping with R</a></div><div class="digest-card__date"><span class="digest-card__label">February 8, 2022</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://github.com/steviep42">Steve Pittard</a></span></div></div></div><div class="digest-card__summary">A book explaining how to web scrape using R. Walks users through extensive code and real-life examples scraping websites such as IMDB, PubMed, and AAUP Faculty Compensation. Chapters are fairly self-contained and cover topics such as static page scraping, XML and JSON, APIs, and sentiment analysis.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>GitHub, vector space model of a document, bag of words, word distributions, lexical diversity, sentiment, machine learning, support vector machines, k-NN models, random forests/trees, bursts and memes</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/screen-lots-of-clicking.jpg" alt="D-Lab Python Web Scraping Workshop image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://github.com/dlab-berkeley/Python-Web-Scraping">D-Lab Python Web Scraping Workshop</a></div><div class="digest-card__date"><span class="digest-card__label">2024</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://github.com/tomvannuenen">Tom van Neunen</a></span>, <span><a href="https://github.com/pssachdeva">Pratik Sachdeva</a></span></div></div></div><div class="digest-card__summary">This GitHub repository contains links to Google Slides and Jupyter slides with sample code and practice problems that are used in an interactive workshop taught by UC Berkeley's D-Lab. The material covers basic web scraping methods using Python such as the requests and beautifulsoup4 packages.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>GitHub, Python, requests, BeautifulSoup, beautifulsoup4, lxml, JSON, HTML tags, href elements</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/phone-with-location.jpg" alt="D-Lab Python Geospatial Fundamentals Workshop image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://github.com/dlab-berkeley/Python-Geospatial-Fundamentals-Legacy">D-Lab Python Geospatial Fundamentals Workshop</a></div><div class="digest-card__date"><span class="digest-card__label">2022</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://github.com/hikari-murayama">Hikari Murayama</a></span>, <span><a href="https://github.com/pattyf">Patty Frontiera</a></span>, <span><a href="https://github.com/erthward">Drew Terasaki Hart</a></span>, <span><a href="https://github.com/pssachdeva">Pratik Sachdeva</a></span>, <span><a href="https://github.com/aculich">Aaron Culich</a></span></div></div></div><div class="digest-card__summary">This GitHub repository contains the materials related to UC Berkey's D-Lab's 6-hour introduction to working with geospatial data in Python. Learn how to import, visualize, and analyze geospatial data using GeoPandas in Python.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>GitHub, Python, spatial DataFrames, GeoPandas, GeoDataFrames, matplotlib, vector spatial data, geoprocessing, color palettes, data classification</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/hierarchy-graph.jpg" alt="D-Lab Python Machine Learning Workshop image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://github.com/dlab-berkeley/Python-Machine-Learning">D-Lab Python Machine Learning Workshop</a></div><div class="digest-card__date"><span class="digest-card__label">2024</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://github.com/dlab-berkeley/Python-Machine-Learning?tab=readme-ov-file#contributors">D-Lab contributors</a></span></div></div></div><div class="digest-card__summary">This GitHub repository contains the materials related to UC Berkey's D-Lab's 6 hour introduction to machine learning in Python. Learn how to perform classification, regression, clustering, and do model selection using scikit-learn in Python.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>GitHub, Python, machine learning, regression, regularization, preprocessing, classification, scikit-learn</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/quotation-marks.jpg" alt="D-Lab Python Text Analysis Workshop image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://github.com/dlab-berkeley/Python-Text-Analysis">D-Lab Python Text Analysis Workshop</a></div><div class="digest-card__date"><span class="digest-card__label">2022</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://github.com/dlab-berkeley/Python-Text-Analysis?tab=readme-ov-file#contributors">D-Lab contributors</a></span></div></div></div><div class="digest-card__summary">This GitHub repository contains the materials related to UC Berkey's D-Lab's 12 hour introduction to text analysis with Python. Learn how to perform bag-of-words, sentiment analysis, topic modeling, word embeddings, and more, using scikit-learn, NLTK, Gensim, and spaCy in Python.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>GitHub, Python, text analysis, bag-of-words, sentiment analysis, topic modeling, word embeddings, scikit-learn, NLTK, Gensim, spaCy</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/horizontal-nodes.jpg" alt="D-Lab Python Deep Learning Workshop image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://github.com/dlab-berkeley/Python-Deep-Learning">D-Lab Python Deep Learning Workshop</a></div><div class="digest-card__date"><span class="digest-card__label">2022</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://github.com/seanmperez">Sean Perez</a></span>, <span><a href="https://github.com/seangariando">seangariando</a></span></div></div></div><div class="digest-card__summary">This GitHub repository contains the materials related to UC Berkey's D-Lab's 6 hour introduction to deep learning with Python. Convey the basics of deep learning in Python using keras on image datasets. Students are empowered with a general grasp of deep learning, example code that they can modify, a working computational environment, and resources for further study.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>GitHub, Python, deep learning, Jupyter, dataset splitting, feed forward neural networks, vanilla neural networks, convolutional neural networks, image classification</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/upward-graph.jpg" alt="D-Lab Python Data Visualization Workshop image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://github.com/dlab-berkeley/Python-Data-Visualization">D-Lab Python Data Visualization Workshop</a></div><div class="digest-card__date"><span class="digest-card__label">2022</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://github.com/dlab-berkeley/Python-Data-Visualization/graphs/contributors">D-Lab contributors</a></span></div></div></div><div class="digest-card__summary">This GitHub repository contains the materials related to UC Berkey's D-Lab's 3 hour introduction to data visualization with Python. Learn how to create histograms, bar plots, box plots, scatter plots, compound figures, and more, using matplotlib and seaborn.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>GitHub, Python, data visualization, histograms, bar plots, box plots, scatter plots, compound figures, matplotlib, seaborn</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/man-programming.jpg" alt="D-Lab Python Fundamentals Workshop image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://github.com/dlab-berkeley/Python-Fundamentals">D-Lab Python Fundamentals Workshop</a></div><div class="digest-card__date"><span class="digest-card__label">2024</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://github.com/tomvannuenen">Tom van Nuenen</a></span>, <span><a href="https://github.com/pssachdeva">Pratik Sachdeva</a></span>, <span><a href="https://github.com/aculich">Aaron Culich</a></span></div></div></div><div class="digest-card__summary">This GitHub repository contains the materials related to UC Berkey's D-Lab's 3-part, 6 hour introduction to Python. Learn how to create variables, distinguish data types, use methods, and work with Pandas, using Python and Jupyter.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>GitHub, Python, variables, data types, methods, Pandas, Jupyter</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/woman-programming.jpg" alt="D-Lab Python Intermediate Workshop image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://github.com/dlab-berkeley/Python-Intermediate">D-Lab Python Intermediate Workshop</a></div><div class="digest-card__date"><span class="digest-card__label">2024</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://github.com/dlab-berkeley/Python-Intermediate?tab=readme-ov-file#contributors">D-Lab contributors</a></span></div></div></div><div class="digest-card__summary">This GitHub repository contains the materials related to UC Berkey's D-Lab's 3-part, 6 hour workshop diving deeper into Python. Learn how to create functions, use if-statements and for-loops, and work with Pandas, using Python and Jupyter.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>GitHub, Python, functions, if-statements, for-loops, Pandas, Jupyter</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/floppy-disk.jpg" alt="D-Lab Python Data Wrangling Workshop image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://github.com/dlab-berkeley/Python-Data-Wrangling">D-Lab Python Data Wrangling Workshop</a></div><div class="digest-card__date"><span class="digest-card__label">2024</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="https://github.com/peter-amerkhanian">Peter Amerkhanian</a></span>, <span><a href="https://github.com/pssachdeva">Pratik Sachdeva</a></span>, <span><a href="https://github.com/tomvannuenen">Tom van Nuenen</a></span>, <span><a href="https://github.com/Akesari12">Aniket Kesari</a></span></div></div></div><div class="digest-card__summary">This GitHub repository contains the materials related to UC Berkey's D-Lab's Python data wrangling workshop. Learn how to use the Pandas library, wrangle DataFrame objects, read CSV files, index data, deal with missing data, sort values, merge DataFrames, perform complex grouping, and more.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>GitHub, Python, Pandas, DataFrames, read_csv(), describe(), indexing, missing values, NA values, merging, groupby(), grouping</div></div><div class="digest-card"><div class="digest-card__top"><img class="digest-card__image" src="web_content/images/governance-parthenon.jpg" alt="Legality and Ethics of Web Scraping image"><div class="digest-card__text"><div class="digest-card__title"><a href="https://www.researchgate.net/publication/324907302_Legality_and_Ethics_of_Web_Scraping">Legality and Ethics of Web Scraping</a></div><div class="digest-card__date"><span class="digest-card__label">September 2018</span></div><div class="digest-card__items"><span class="digest-card__label">Author(s) - </span><span><a href="">Vlad Krotov</a></span>, <span><a href="">Leiser Silva</a></span></div></div></div><div class="digest-card__summary">A conference paper presented by Vlad Krotov of Murray State University and Leiser Silva of the University of Houston in the Twenty-Fourth Americas Conference on Information Systems in New Orleans in September 2018. The 5-page PDF, accessible for free, reviews the U.S. legal literature on the subject and discusses legality and ethics of web scraping and web crawling.</div><div class="digest-card__keywords"><span class="digest-card__label">Keywords: </span>big data, web data, web scraping, web crawling, law, ethics</div></div></div>
</div>
<script>
let resourcesData = [];
async function fetchResources() {
const response = await fetch('web_content/data/web-scraping-resources.json');
resourcesData = await response.json();
displayResources(resourcesData);
}
function displayResources(data) {
const container = document.getElementById('resources-container');
container.innerHTML = '';
data.forEach(resource => {
const card = document.createElement('div');
card.className = 'digest-card';
const topSection = document.createElement('div');
topSection.className = 'digest-card__top';
const image = document.createElement('img');
image.className = 'digest-card__image';
image.src = resource.image;
image.alt = `${resource.title} image`;
topSection.appendChild(image);
const textContainer = document.createElement('div');
textContainer.className = 'digest-card__text';
const title = document.createElement('div');
title.className = 'digest-card__title';
title.innerHTML = `<a href="${resource.link}">${resource.title}</a>`;
textContainer.appendChild(title);
const date = document.createElement('div');
date.className = 'digest-card__date';
date.innerHTML = `<span class="digest-card__label">${resource.date}</span>`;
textContainer.appendChild(date);
const authors = document.createElement('div');
authors.className = 'digest-card__items';
authors.innerHTML = `<span class="digest-card__label">Author(s) - </span>${resource.authors.map(author => `<span><a href="${author.link}">${author.name}</a></span>`).join(', ')}`;
textContainer.appendChild(authors);
topSection.appendChild(textContainer);
card.appendChild(topSection);
const description = document.createElement('div');
description.className = 'digest-card__summary';
description.textContent = resource.description;
card.appendChild(description);
const keywords = document.createElement('div');
keywords.className = 'digest-card__keywords';
keywords.innerHTML = `<span class="digest-card__label">Keywords: </span>${resource.keywords.join(', ')}`;
card.appendChild(keywords);
container.appendChild(card);
});
}
fetchResources();
// Function to fetch and display GDP data
async function fetchGDPData() {
const response = await fetch('web_content/data/gdp-data.csv');
const data = await response.text();
const parsedData = Papa.parse(data, { header: true }).data;
const labels = parsedData.map(row => row.Date);
const gdpValues = parsedData.map(row => parseFloat(row.GDP));
const ctx = document.getElementById('gdpChart').getContext('2d');
new Chart(ctx, {
type: 'line',
data: {
labels: labels,
datasets: [{
label: 'US GDP',
data: gdpValues,
borderColor: 'rgba(75, 192, 192, 1)',
backgroundColor: 'rgba(75, 192, 192, 0.2)',
borderWidth: 1
}]
},
options: {
responsive: true,
scales: {
x: {
display: true,
title: {
display: true,
text: 'Year'
}
},
y: {
display: true,
title: {
display: true,
text: 'GDP (in billions)'
}
}
},
plugins: {
tooltip: {
enabled: true,
mode: 'nearest',
intersect: false,
callbacks: {
label: function(context) {
let label = context.dataset.label || '';
if (label) {
label += ': ';
}
if (context.parsed.y !== null) {
label += new Intl.NumberFormat('en-US', { style: 'currency', currency: 'USD' }).format(context.parsed.y);
}
return label;
}
}
}
}
}
});
}
fetchGDPData();
</script>
<div class="container">
<h2>Interactive Graph</h2>
<p>The following graph contains United States nominal Gross Domestic Product data from Q1 1947 to Q1 2024. Data is courtesy of the Federal Reserve Bank of St. Louis "FRED" service. </p>
<div class="container">
<canvas id="gdpChart" width="622" height="311" style="display: block; box-sizing: border-box; height: 311px; width: 622px;"></canvas>
</div>
</div>
</body></html>
We did it! Now we have HTML content, just as before. But there's a crucial difference: our dynamic content is pre-loaded into the HTML code.
Let's try re-running the code from the previous section to this new HTML output. Hopefully, we can access the dynamic elements of the webpage.
# Use BeautifulSoup to parse the html_content
soup = BeautifulSoup(html_content, 'html.parser')
# Scrape titles and links
elements = soup.select('div.digest-card__title a')
# Initialize lists
Titles = []
Links = []
for el in elements:
# Obtain the link to the resource
link = el['href'] # 'href' is a HTML lingo for hyperlinks.
# Obtain the title of the resource
title = el.text
# Append the entries to each list
Titles.append(title)
Links.append(link)
# Print the results
print(Titles)
print(Links)
['Introduction to Data Science Using Python', 'Webscraping in R (and a little Python and Excel too)', 'Populating the page: how browsers work', 'What is DNS? | How DNS works', 'How the web works', 'A Practical Introduction to Web Scraping in Python', 'Automate the Boring Stuff: Web Scraping (Chapter 12)', 'Getting Started (with Selenium)', 'Getting started with the web', 'roundup', 'Text Mining with R: A Tidy Approach', 'Text as Data', 'Text as Data (Spring 2021, NYU)', 'Web Scraping with R', 'D-Lab Python Web Scraping Workshop', 'D-Lab Python Geospatial Fundamentals Workshop', 'D-Lab Python Machine Learning Workshop', 'D-Lab Python Text Analysis Workshop', 'D-Lab Python Deep Learning Workshop', 'D-Lab Python Data Visualization Workshop', 'D-Lab Python Fundamentals Workshop', 'D-Lab Python Intermediate Workshop', 'D-Lab Python Data Wrangling Workshop', 'Legality and Ethics of Web Scraping'] ['https://github.com/DistrictDataLabs/Brookings_Python_DS', 'https://example.com/secret', 'https://developer.mozilla.org/en-US/docs/Web/Performance/How_browsers_work', 'https://www.cloudflare.com/learning/dns/what-is-dns/', 'https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web/How_the_Web_works', 'https://realpython.com/python-web-scraping-practical-introduction/', 'https://automatetheboringstuff.com/2e/chapter12/', 'https://www.selenium.dev/documentation/webdriver/getting_started/', 'https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web', 'https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web', 'https://www.tidytextmining.com/', 'https://cbail.github.io/textasdata/Text_as_Data.html', 'https://github.com/ArthurSpirling/text-as-data-class-spring2021', 'https://steviep42.github.io/webscraping/book', 'https://github.com/dlab-berkeley/Python-Web-Scraping', 'https://github.com/dlab-berkeley/Python-Geospatial-Fundamentals-Legacy', 'https://github.com/dlab-berkeley/Python-Machine-Learning', 'https://github.com/dlab-berkeley/Python-Text-Analysis', 'https://github.com/dlab-berkeley/Python-Deep-Learning', 'https://github.com/dlab-berkeley/Python-Data-Visualization', 'https://github.com/dlab-berkeley/Python-Fundamentals', 'https://github.com/dlab-berkeley/Python-Intermediate', 'https://github.com/dlab-berkeley/Python-Data-Wrangling', 'https://www.researchgate.net/publication/324907302_Legality_and_Ethics_of_Web_Scraping']
We did it!
Sample code: APIs¶
APIs - when available - are my favorite way to collect data from the internet. They're also a bit of a secret method - there's not many tutorials on using hidden APIs for web scraping!
You're already familiar with the main tool you'll need for this: the requests package.
Viewing network requests¶
Remember the dyamically-rendered content we saw in the last section, and how we had to use selenium to access it?
Sometimes, there's a simpler way: we can import the data directly, without opening a browser or dealing with any HTML at all.
API access isn't always possible. We'll have to inspect the HTTP requests that our browser sends to the server and the responses sent from the server to our browser to determine whether there's any information that we can intercept.
The easiest way to view this activity is to access the network requests pane.
With your browser open on the webpage in question,
- right click,
- select "Inspect element",
- then select the "Network" tab.
Here, the network requests pane is open but empty. Since the website already loaded, the requests are done.
To view the requests as they happen, simply refresh the webpage with the network requests tab open.
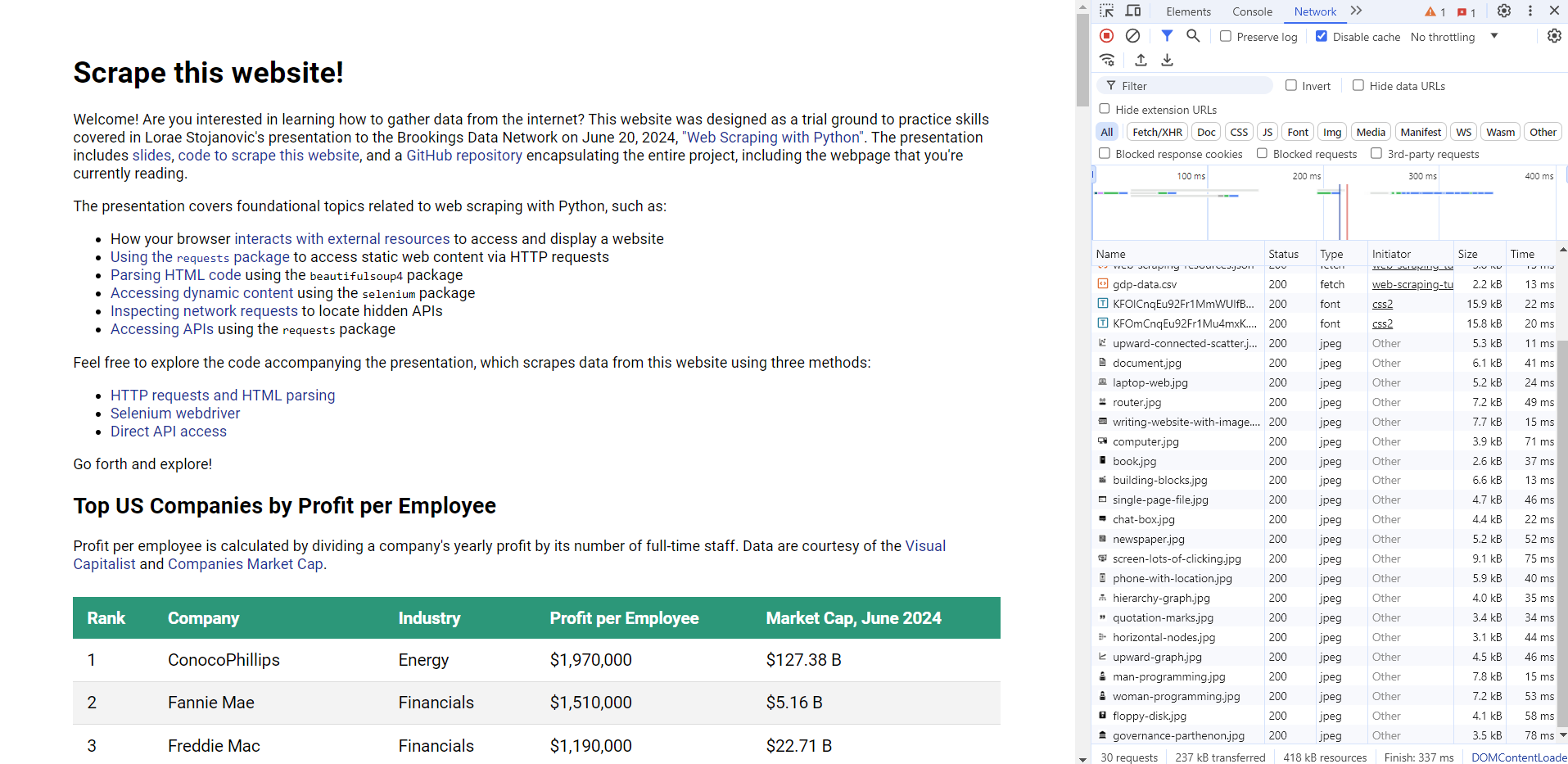
Recall the procedure that the browser uses to access data:
- DNS lookup
- Initial HTTP request
- Server response
- Parsing HTML + additional requests
- Assembling the page
The first request we see is the initial HTTP request (step 2). The response from the server is the initial HTML file (step 3), which your browser begins to parse.

As your browser parses this HTML file, it encounters additional references that it needs, causing it to make more requests for external resources (step 4).

Monitoring network requests¶
Websites make many requests, and API requests are often subtle. It can be tricky to tell which - if any- exchange the information you seek, since their titles are often uninformative.
I typically start by sorting requests by Type. API requests tend to be of type xhr or fetch, but this is not a hard and fast rule.
You can also look at the title of the request and its headers. If the request contains the string "api" in it, that can be a good tell.
When in doubt, inspect the responses. Do they contain the data you seek?
For especially tough cases, poking around where you think APIs might be used on the frontend, such as navigating forward on a menu, displaying more years on an interactive graph, or searching for things in the website's the search bar can help.
If those actions trigger an API request, the network requests pane will show new entries at the bottom.
Live demo: Find the API requests¶
This website uses 2 API requests, which each load a file:
- web-scraping-resources.json
- gdp-data.csv
Let's learn how to access these files using the requests package.
Using requests to access APIs¶
Fun fact: If the request is a GET request, you can oftentimes request the API quickly and cheaply by copying and pasting the request URL into your browser's navigation bar.
(In my experience, this works about 80% of the time.)
Translating this process to Python code is very easy.
Let's start by importing the requests library and assigning some headers.
import requests
my_headers = {
'User-Agent': (
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/122.0.6261.112 Safari/537.36'
),
'Accept': (
'text/html,application/xhtml+xml,application/xml;q=0.9,'
'image/avif,image/webp,image/apng,*/*;q=0.8,'
'application/signed-exchange;v=b3;q=0.7'
)
}
Next, we copy the request URL.
my_request_url = "https://lorae.github.io/web-scraping-tutorial/web_content/data/web-scraping-resources.json"
We then proceed exactly as we did earlier in this presentation:
session_arguments = requests.Request(method='GET',
url=my_request_url,
headers=my_headers)
session = requests.Session()
prepared_request = session.prepare_request(session_arguments)
response: requests.Response = session.send(prepared_request)
But this time, the response is not HTML code that we have to clean. Instead, it's a file in a JSON format.[12]
Accessing the data is in this format is very strightforward. We simply retrieve it using the json() method of the response object.
[12] JSON, or JavaScript Object Notation, is a file format commonly used for transferring data over the internet. If you web scrape, you will encounter it frequently. For more information, visit: https://www.w3schools.com/whatis/whatis_json.asp
json_data = response.json()
json_data
[{'title': 'Introduction to Data Science Using Python',
'date': 'June 5, 2020',
'link': 'https://github.com/DistrictDataLabs/Brookings_Python_DS',
'authors': [{'name': 'District Data Labs',
'link': 'https://districtdatalabs.silvrback.com/'}],
'description': 'A GitHub repository containing slides and code introducing an audience with no Python experience to data science tools in Python.',
'keywords': ['Python',
'data science',
'data structures',
'loops',
'list comprehension',
'conditional evaluation',
'functions',
'Pandas',
'DataFrames',
'data visualization',
'plotly',
'hypothesis tests',
'regression analysis',
'machine learning'],
'source': 'GitHub',
'image': 'web_content/images/upward-connected-scatter.jpg'},
{'title': 'Webscraping in R (and a little Python and Excel too)',
'date': 'February 22, 2023',
'link': 'https://example.com/secret',
'authors': [{'name': 'Valerie Wirtschafter', 'link': '#'},
{'name': 'Mimi Majumder', 'link': '#'}],
'description': 'A thorough introductory guide to web scraping for R users, suitable for an absolute beginner. Explains using CSS selectors, scheduling jobs, and scraping tables, images, and PDFs, among other topics.',
'keywords': ['copy-paste',
'APIs',
'DOM parsing',
'HTML',
'CSS',
'polite',
'rvest',
'paginated webpages',
'cronR',
'pdftools',
'requests',
'BeautifulSoup',
'Excel'],
'source': 'Brookings Internal',
'image': 'web_content/images/document.jpg'},
{'title': 'Populating the page: how browsers work',
'date': 'July 20, 2023',
'link': 'https://developer.mozilla.org/en-US/docs/Web/Performance/How_browsers_work',
'authors': [{'name': 'MDN contributors',
'link': 'https://developer.mozilla.org/en-US/docs/Web/Performance/How_browsers_work/contributors.txt'}],
'description': 'A concise blog post, aimed at developers, that explains how browsers provide their users with a web experience.',
'keywords': ['DNS lookup',
'TCP handshake',
'TLS negotiation',
'HTTP GET request',
'response',
'parsing',
'DOM tree',
'CSSOM tree',
'JavaScript compilation',
'render',
'paint'],
'source': 'Mozilla Developer Network',
'image': 'web_content/images/laptop-web.jpg'},
{'title': 'What is DNS? | How DNS works',
'date': '',
'link': 'https://www.cloudflare.com/learning/dns/what-is-dns/',
'authors': [{'name': '', 'link': '#'}],
'description': 'A blog post explaining the DNS resolution process. A useful starting point for laypeople interested in learning more about the process.',
'keywords': ['DNS server',
'IP address',
'recursive DNS resolver',
'DNS lookup',
'DNS caching'],
'source': 'Cloudflare',
'image': 'web_content/images/router.jpg'},
{'title': 'How the web works',
'date': 'November 17, 2023',
'link': 'https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web/How_the_Web_works',
'authors': [{'name': 'MDN contributors',
'link': 'https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web/How_the_Web_works/contributors.txt'}],
'description': 'A high-level blog post accessible to beginners, aimed at developers, that explains how a phone or computer browser displays a webpage. Part of a longer series of blog posts that may be helpful for those hoping to learn more about browsers in depth.',
'keywords': ['clients',
'servers',
'requests',
'responses',
'TCP',
'IP address',
'DNS',
'HTTP',
'component files',
'code files',
'assets',
'packets'],
'source': 'Mozilla Developer Network',
'image': 'web_content/images/writing-website-with-image.jpg'},
{'title': 'A Practical Introduction to Web Scraping in Python',
'date': '',
'link': 'https://realpython.com/python-web-scraping-practical-introduction/',
'authors': [{'name': 'David Amos',
'link': 'https://realpython.com/python-web-scraping-practical-introduction/#author'}],
'description': 'A tutorial aimed at beginners to web scraping with some prior knowledge of Python. Focuses mainly on building skills with HTML parsing using BeautifulSoup and interacting with the browser using MechanicalSoup. After this tutorial, users will likely be ready to learn to use Selenium.',
'keywords': ['HTML',
'regex',
'regular expressions',
'BeautifulSoup',
'MechanicalSoup'],
'source': 'Real Python',
'image': 'web_content/images/computer.jpg'},
{'title': 'Automate the Boring Stuff: Web Scraping (Chapter 12)',
'date': '',
'link': 'https://automatetheboringstuff.com/2e/chapter12/',
'authors': [{'name': 'Al Sweigart',
'link': 'https://realpython.com/python-web-scraping-practical-introduction/#author'}],
'description': 'A free online textbook introducing users to concepts in Python. This chapter assumes basic proficiency in Python from reading previous chapters. Walks users through inspecting the HTML code underlying websites using developer tools on the web browser, parsing the content using BeautifulSoup, and rendering interactive pages using a Selenium webdriver.',
'keywords': ['requests',
'GET requests',
'HTML',
'View page source',
'Inspect element',
'Developer tools',
'HTML elements',
'BeautifulSoup',
'select method',
'Selenium'],
'source': 'Real Python',
'image': 'web_content/images/book.jpg'},
{'title': 'Getting Started (with Selenium)',
'date': 'January 12, 2022',
'link': 'https://www.selenium.dev/documentation/webdriver/getting_started/',
'authors': [{'name': '', 'link': '#'}],
'description': 'Generalized documentation for Selenium using multiple programming languages (like Python), including installing the library and organizing and executing Selenium code. Includes several lines of sample code illustrating how to start and end a session, find elements, and take action on elements.',
'keywords': ['webdrivers',
'browsers',
'waits',
'elements',
'interactions',
'sample code',
'Python'],
'source': 'Selenium',
'image': 'web_content/images/laptop-web.jpg'},
{'title': 'Getting started with the web',
'date': 'February 4, 2024',
'link': 'https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web',
'authors': [{'name': 'MDN contributors',
'link': 'https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web/contributors.txt'}],
'description': 'A high-quality series of blog posts that guides skills levels ranging from absolute beginners to those with more intermediate understanding through the process of building a website. Comprised of short, accessible blog posts covering many topics, including how the web works, and introductions to HTML, CSS, and JavaScript. Aimed at developers, but serves as useful background for more general audiences and those interested in understanding the web better for web scraping.',
'keywords': ['HTML', 'CSS', 'JavaScript', 'tools and testing'],
'source': 'Mozilla Developer Network',
'image': 'web_content/images/building-blocks.jpg'},
{'title': 'roundup',
'date': 'June 16, 2024',
'link': 'https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web',
'authors': [{'name': 'Lorae Stojanovic', 'link': '#'}],
'description': "Lorae's (the creater of this website) GitHub repository which scrapes pre-print academic economics papers from 20+ sources; presents titles, abstracts, authors and hyperlinks on an online dashboard. Auto-updates daily using GitHub Actions workflow. May be helpful sample code for those interested in web scraping in Python or automating their scraping using GitHub Actions.",
'keywords': ['web scraping', 'Python', 'GitHub Actions', 'Streamlit'],
'source': 'GitHub',
'image': 'web_content/images/single-page-file.jpg'},
{'title': 'Text Mining with R: A Tidy Approach',
'date': '2023',
'link': 'https://www.tidytextmining.com/',
'authors': [{'name': 'Julia Silge', 'link': 'https://juliasilge.com/'},
{'name': 'David Robinson', 'link': 'http://varianceexplained.org/'}],
'description': 'A free, open-source book by the authors of the `tidytext` R package that introduces text mining in R. The authors provide extensive examples of text analysis in action, including sentiment analysis, the tf-idf statistic, n-grams, and document-term matrics. Real examples use data from Twitter archives, NASA datasets, and more.',
'keywords': ['tidytext',
'unnest_tokens()',
'sentiments dataset',
'tf-idf statistic',
'n-grams',
'document-term matrices',
'tidy() method'],
'source': '',
'image': 'web_content/images/chat-box.jpg'},
{'title': 'Text as Data',
'date': '2023',
'link': 'https://cbail.github.io/textasdata/Text_as_Data.html',
'authors': [{'name': 'Chris Bail', 'link': 'https://www.chrisbail.net/'}],
'description': 'A free, online course by a Professor of Sociology, Public Policy, and Data Science at Duke University. The course materials - which involve programming in R - are available on his GitHub page. His course covers topics such as APIs, basic text analysis, dictionary-based text analysis, topic modeling, text networks, and word embeddings.',
'keywords': ['GitHub',
'text as data',
'screen-scraping',
'APIs',
'basic text analysis',
'dictionary-based text analysis',
'topic modeling',
'text networks',
'word embeddings'],
'source': 'Duke University',
'image': 'web_content/images/chat-box.jpg'},
{'title': 'Text as Data (Spring 2021, NYU)',
'date': 'January 8, 2021',
'link': 'https://github.com/ArthurSpirling/text-as-data-class-spring2021',
'authors': [{'name': 'Arthur Sprling',
'link': 'https://github.com/ArthurSpirling'}],
'description': 'An NYU course taught in spring 2021, aimed at students who have taken at least one class in statistics or inference and who have a basic knowledge of calculus, progability, densities, distributions, statistical tests, hypothesis testing, maximum likelihood, and generalized linear models. The course is applied and uses R as a programming language.',
'keywords': ['GitHub',
'vector space model of a document',
'bag of words',
'word distributions',
'lexical diversity',
'sentiment',
'machine learning',
'support vector machines',
'k-NN models',
'random forests/trees',
'bursts and memes'],
'source': 'New York University',
'image': 'web_content/images/newspaper.jpg'},
{'title': 'Web Scraping with R',
'date': 'February 8, 2022',
'link': 'https://steviep42.github.io/webscraping/book',
'authors': [{'name': 'Steve Pittard',
'link': 'https://github.com/steviep42'}],
'description': 'A book explaining how to web scrape using R. Walks users through extensive code and real-life examples scraping websites such as IMDB, PubMed, and AAUP Faculty Compensation. Chapters are fairly self-contained and cover topics such as static page scraping, XML and JSON, APIs, and sentiment analysis.',
'keywords': ['GitHub',
'vector space model of a document',
'bag of words',
'word distributions',
'lexical diversity',
'sentiment',
'machine learning',
'support vector machines',
'k-NN models',
'random forests/trees',
'bursts and memes'],
'source': 'New York University',
'image': 'web_content/images/newspaper.jpg'},
{'title': 'D-Lab Python Web Scraping Workshop',
'date': '2024',
'link': 'https://github.com/dlab-berkeley/Python-Web-Scraping',
'authors': [{'name': 'Tom van Neunen',
'link': 'https://github.com/tomvannuenen'},
{'name': 'Pratik Sachdeva', 'link': 'https://github.com/pssachdeva'}],
'description': "This GitHub repository contains links to Google Slides and Jupyter slides with sample code and practice problems that are used in an interactive workshop taught by UC Berkeley's D-Lab. The material covers basic web scraping methods using Python such as the requests and beautifulsoup4 packages.",
'keywords': ['GitHub',
'Python',
'requests',
'BeautifulSoup',
'beautifulsoup4',
'lxml',
'JSON',
'HTML tags',
'href elements'],
'source': 'UC Berkeley D-Lab',
'image': 'web_content/images/screen-lots-of-clicking.jpg'},
{'title': 'D-Lab Python Geospatial Fundamentals Workshop',
'date': '2022',
'link': 'https://github.com/dlab-berkeley/Python-Geospatial-Fundamentals-Legacy',
'authors': [{'name': 'Hikari Murayama',
'link': 'https://github.com/hikari-murayama'},
{'name': 'Patty Frontiera', 'link': 'https://github.com/pattyf'},
{'name': 'Drew Terasaki Hart', 'link': 'https://github.com/erthward'},
{'name': 'Pratik Sachdeva', 'link': 'https://github.com/pssachdeva'},
{'name': 'Aaron Culich', 'link': 'https://github.com/aculich'}],
'description': "This GitHub repository contains the materials related to UC Berkey's D-Lab's 6-hour introduction to working with geospatial data in Python. Learn how to import, visualize, and analyze geospatial data using GeoPandas in Python.",
'keywords': ['GitHub',
'Python',
'spatial DataFrames',
'GeoPandas',
'GeoDataFrames',
'matplotlib',
'vector spatial data',
'geoprocessing',
'color palettes',
'data classification'],
'source': 'UC Berkeley D-Lab',
'image': 'web_content/images/phone-with-location.jpg'},
{'title': 'D-Lab Python Machine Learning Workshop',
'date': '2024',
'link': 'https://github.com/dlab-berkeley/Python-Machine-Learning',
'authors': [{'name': 'D-Lab contributors',
'link': 'https://github.com/dlab-berkeley/Python-Machine-Learning?tab=readme-ov-file#contributors'}],
'description': "This GitHub repository contains the materials related to UC Berkey's D-Lab's 6 hour introduction to machine learning in Python. Learn how to perform classification, regression, clustering, and do model selection using scikit-learn in Python.",
'keywords': ['GitHub',
'Python',
'machine learning',
'regression',
'regularization',
'preprocessing',
'classification',
'scikit-learn'],
'source': 'UC Berkeley D-Lab',
'image': 'web_content/images/hierarchy-graph.jpg'},
{'title': 'D-Lab Python Text Analysis Workshop',
'date': '2022',
'link': 'https://github.com/dlab-berkeley/Python-Text-Analysis',
'authors': [{'name': 'D-Lab contributors',
'link': 'https://github.com/dlab-berkeley/Python-Text-Analysis?tab=readme-ov-file#contributors'}],
'description': "This GitHub repository contains the materials related to UC Berkey's D-Lab's 12 hour introduction to text analysis with Python. Learn how to perform bag-of-words, sentiment analysis, topic modeling, word embeddings, and more, using scikit-learn, NLTK, Gensim, and spaCy in Python.",
'keywords': ['GitHub',
'Python',
'text analysis',
'bag-of-words',
'sentiment analysis',
'topic modeling',
'word embeddings',
'scikit-learn',
'NLTK',
'Gensim',
'spaCy'],
'source': 'UC Berkeley D-Lab',
'image': 'web_content/images/quotation-marks.jpg'},
{'title': 'D-Lab Python Deep Learning Workshop',
'date': '2022',
'link': 'https://github.com/dlab-berkeley/Python-Deep-Learning',
'authors': [{'name': 'Sean Perez', 'link': 'https://github.com/seanmperez'},
{'name': 'seangariando', 'link': 'https://github.com/seangariando'}],
'description': "This GitHub repository contains the materials related to UC Berkey's D-Lab's 6 hour introduction to deep learning with Python. Convey the basics of deep learning in Python using keras on image datasets. Students are empowered with a general grasp of deep learning, example code that they can modify, a working computational environment, and resources for further study.",
'keywords': ['GitHub',
'Python',
'deep learning',
'Jupyter',
'dataset splitting',
'feed forward neural networks',
'vanilla neural networks',
'convolutional neural networks',
'image classification'],
'source': 'UC Berkeley D-Lab',
'image': 'web_content/images/horizontal-nodes.jpg'},
{'title': 'D-Lab Python Data Visualization Workshop',
'date': '2022',
'link': 'https://github.com/dlab-berkeley/Python-Data-Visualization',
'authors': [{'name': 'D-Lab contributors',
'link': 'https://github.com/dlab-berkeley/Python-Data-Visualization/graphs/contributors'}],
'description': "This GitHub repository contains the materials related to UC Berkey's D-Lab's 3 hour introduction to data visualization with Python. Learn how to create histograms, bar plots, box plots, scatter plots, compound figures, and more, using matplotlib and seaborn.",
'keywords': ['GitHub',
'Python',
'data visualization',
'histograms',
'bar plots',
'box plots',
'scatter plots',
'compound figures',
'matplotlib',
'seaborn'],
'source': 'UC Berkeley D-Lab',
'image': 'web_content/images/upward-graph.jpg'},
{'title': 'D-Lab Python Fundamentals Workshop',
'date': '2024',
'link': 'https://github.com/dlab-berkeley/Python-Fundamentals',
'authors': [{'name': 'Tom van Nuenen',
'link': 'https://github.com/tomvannuenen'},
{'name': 'Pratik Sachdeva', 'link': 'https://github.com/pssachdeva'},
{'name': 'Aaron Culich', 'link': 'https://github.com/aculich'}],
'description': "This GitHub repository contains the materials related to UC Berkey's D-Lab's 3-part, 6 hour introduction to Python. Learn how to create variables, distinguish data types, use methods, and work with Pandas, using Python and Jupyter.",
'keywords': ['GitHub',
'Python',
'variables',
'data types',
'methods',
'Pandas',
'Jupyter'],
'source': 'UC Berkeley D-Lab',
'image': 'web_content/images/man-programming.jpg'},
{'title': 'D-Lab Python Intermediate Workshop',
'date': '2024',
'link': 'https://github.com/dlab-berkeley/Python-Intermediate',
'authors': [{'name': 'D-Lab contributors',
'link': 'https://github.com/dlab-berkeley/Python-Intermediate?tab=readme-ov-file#contributors'}],
'description': "This GitHub repository contains the materials related to UC Berkey's D-Lab's 3-part, 6 hour workshop diving deeper into Python. Learn how to create functions, use if-statements and for-loops, and work with Pandas, using Python and Jupyter.",
'keywords': ['GitHub',
'Python',
'functions',
'if-statements',
'for-loops',
'Pandas',
'Jupyter'],
'source': 'UC Berkeley D-Lab',
'image': 'web_content/images/woman-programming.jpg'},
{'title': 'D-Lab Python Data Wrangling Workshop',
'date': '2024',
'link': 'https://github.com/dlab-berkeley/Python-Data-Wrangling',
'authors': [{'name': 'Peter Amerkhanian',
'link': 'https://github.com/peter-amerkhanian'},
{'name': 'Pratik Sachdeva', 'link': 'https://github.com/pssachdeva'},
{'name': 'Tom van Nuenen', 'link': 'https://github.com/tomvannuenen'},
{'name': 'Aniket Kesari', 'link': 'https://github.com/Akesari12'}],
'description': "This GitHub repository contains the materials related to UC Berkey's D-Lab's Python data wrangling workshop. Learn how to use the Pandas library, wrangle DataFrame objects, read CSV files, index data, deal with missing data, sort values, merge DataFrames, perform complex grouping, and more.",
'keywords': ['GitHub',
'Python',
'Pandas',
'DataFrames',
'read_csv()',
'describe()',
'indexing',
'missing values',
'NA values',
'merging',
'groupby()',
'grouping'],
'source': 'UC Berkeley D-Lab',
'image': 'web_content/images/floppy-disk.jpg'},
{'title': 'Legality and Ethics of Web Scraping',
'date': 'September 2018',
'link': 'https://www.researchgate.net/publication/324907302_Legality_and_Ethics_of_Web_Scraping',
'authors': [{'name': 'Vlad Krotov', 'link': ''},
{'name': 'Leiser Silva', 'link': ''}],
'description': 'A conference paper presented by Vlad Krotov of Murray State University and Leiser Silva of the University of Houston in the Twenty-Fourth Americas Conference on Information Systems in New Orleans in September 2018. The 5-page PDF, accessible for free, reviews the U.S. legal literature on the subject and discusses legality and ethics of web scraping and web crawling.',
'keywords': ['big data',
'web data',
'web scraping',
'web crawling',
'law',
'ethics'],
'source': 'ResearchGate',
'image': 'web_content/images/governance-parthenon.jpg'}]
We can easily access the entries we need as follows.
# Now json_data is a list of dictionaries, each representing an article/resource
for article in json_data:
title = article['title']
print(title)
Introduction to Data Science Using Python Webscraping in R (and a little Python and Excel too) Populating the page: how browsers work What is DNS? | How DNS works How the web works A Practical Introduction to Web Scraping in Python Automate the Boring Stuff: Web Scraping (Chapter 12) Getting Started (with Selenium) Getting started with the web roundup Text Mining with R: A Tidy Approach Text as Data Text as Data (Spring 2021, NYU) Web Scraping with R D-Lab Python Web Scraping Workshop D-Lab Python Geospatial Fundamentals Workshop D-Lab Python Machine Learning Workshop D-Lab Python Text Analysis Workshop D-Lab Python Deep Learning Workshop D-Lab Python Data Visualization Workshop D-Lab Python Fundamentals Workshop D-Lab Python Intermediate Workshop D-Lab Python Data Wrangling Workshop Legality and Ethics of Web Scraping
If the request is a POST request, or if it requires more complex headers, this strategy will not work.
In that case, I recommend using a free software like Postman. The process is simple:
- Right click on the request in the network requests pane.
- Select "Copy as cURL"
- Paste the request into Postman
- Auto generate Python code by clicking the
</>button
That's it!¶
Resources from this presentation:
- My GitHub repository containing all slides, sample code, and website source code
- Link to this presentation
- Link to the sample code
- Link to the web scraping instructional website